Zookeeper
Linearizability 可线性化
顺序一致性定义:如果一个并发执行过程所包含的所有读写操作能够重排成一个全局线性有序的序列,并且这个序列满足以下两个条件,那么这个并发执行过程就是满足顺序一致性的:
条件I:重排后的序列中每一个读操作返回的值,必须等于前面对同一个数据对象的最近一次写操作所写入的值。
条件II:原来每个进程中各个操作的执行先后顺序,在这个重排后的序列中必须保持一致。
在顺序一致性中,我们有可能读到旧版本的数据.
线性一致性定义,与顺序一致性非常相似,也是试图把所有读写操作重排成一个全局线性有序的序列,但除了满足前面的条件I和条件II之外,还要同时满足一个条件:
条件III:不同进程的操作,如果在时间上不重叠,那么它们的执行先后顺序,在这个重排后的序列中必须保持一致。
i.e.强一致性(严格定义)。
If one operation finish before another started, then the one finish first has to come first in the history
If some read sees a particluar written value, then the read must comes after the write in the order
如果时间序列成环,则为非线性化的。
 可参考:一致性模型
可参考:一致性模型
Zookeeper
Terminology:
数据树:data tree,Zookeeper 中所有的数据以树形结构进行组织。
生命周期节点Flag:Regular,生命周期无限,客户端需要调用接口显式的对这类节点进行增删;Ephemeral,生命周期绑定到会话上,会话销毁,节点删除。
顺序节点Flag:sequential,附带分配的一个序列号,由父Znode维护一个单调递增的计数器。可用于实现分布式全局队列,因为顺序号可以强制一个全局顺序。
z - 节点:znode(Zookeeper Node)数据树中的节点,是基本数据单元。
会话:session,客户端与服务器会新建一个会话来标识一个连接,并关联一个超时间隔(timeout),之后客户端每次请求都会通过该会话句柄来进行。Watch 事件的生命周期也是和会话绑定的。
API
Client API
Note that ZooKeeper does not use handles to access znodes.使用路径而不是句柄,可以配合版本信息做成类似幂等的接口,在处理多客户端并发时,更容易实现。
guarantees
Linearizable writes: all requests that update the state of ZooKeeper are serializable and respect precedence.
FIFO client order: all requests from a given client are executed in the order that they were sent by the client.
What if not Leader serve read-request?
Not linearizble~ Just guarentee above.(ZooKeeper只保证了写入操作的线性一致性,并不保证读操作的强一致性。)
当 Server 收到一个请求时,首先进行预处理(Request Processor),如果是写请求,则通过 Zab 协议(Atomic Broadcast)达成一致,然后各自提交到本地数据库(Replicated Database)。对于读请求,直接读取本地数据库中状态后返回。
配置更改
集群中的server只有在看到ready znode存在时才会开始启用新配置。形如:  配合
配合watch trigger机制: 
互斥锁实现
自旋锁: HERD EFFECT( 每次释放互斥资源后,所有的client都会被唤醒并参与到竞争当中)
SEQUENCIAL 方式

解释:
create a "sequential" file
list files
if no lower-numbered
#file, lock is acquired, returnif exists(next-lower-numbered, watch=true) wait for event...
goto 2
Zookeeper 架构
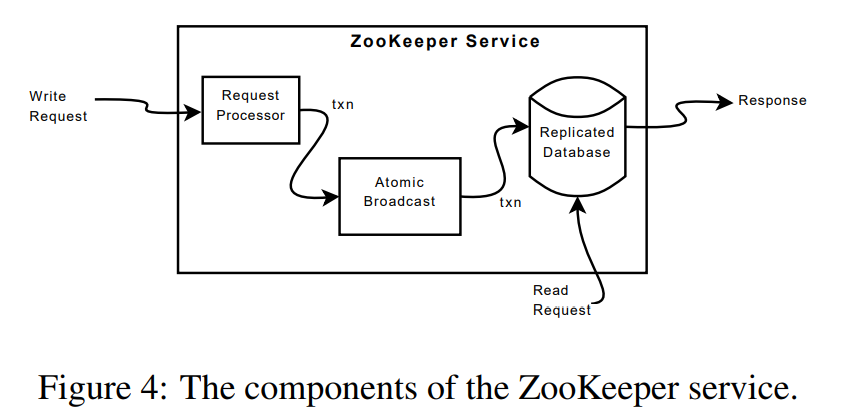
ZooKeeper 使用 Zab 共识协议处理所有的写请求,达成一致,然后写入 WAL,进而应用到本地内存状态机(data tree)。而对于读请求,是直接读取本地数据库即返回。
ZooKeeper 应用场景
请求预处理(Request Processor)
当 Server 收到一个请求时,首先进行预处理。所有更新请求都会被转为幂等(idempotent)的事务(txn),具体方法为: 获取当前状态 -> 计算出目标状态 -> 封装为事务。 由此即可使用类似 CAS 的方式处理并发请求。因此,只要保证所有事务按固定顺序执行,就能避免不同服务器上的数据副本分裂。
原子广播(Atomic Broadcast)
所有更新请求都会被转给 Zookeeper 的 Leader,Leader 首先将事务追加到本地 WAL,然后将变动使用 Zab 协议广播到各个节点,收到过半成功回复之后,Leader 将变动提交(Commit)到本地内存数据库,并广播该 Commit 给 Followers。
为了提高系统吞吐,Zookeeper 使用流水线(pipelined)方式(类似于CPU的SIMD)优化多个请求处理过程。
复制状态机(Replicated Database)
每个服务器都会在本机内存中维护一个 Zookeeper 中所有状态的副本(replica),为了应对宕机重启,ZooKeeper 会定期将状态做快照。不同于普通快照,Zookeeper 称其快照为 fuzzy snapshots,即在做快照时并不上锁,通过 DFS 的方式遍历文件树 Dump 到本地。之后由于异常宕机重启时,只需加最新快照,然后重新执行最新快照之后几条 WAL 即可。由于 WAL 中记录的事务的幂等性特点,即使快照和 WAL 的时间点不完全对应,也不会影响副本间的一致性。
C/S交互
串行写。无论是在全局范围还是具体到一个 Server 本地,所有更新操作都是串行的。在执行某个 Path 数据更新时,该 Server 会触发所有与之连接的 Client 所订阅的 Watch 事件。需要注意,这些事件只保存在 Server 本地,因为他们是和会话关联的,如果 Client 与该 Server 断开连接,会话便会销毁,这些事件也随之消亡。
本地读。为了获取极致性能,Zookeeper 的 Server 直接在本地处理读请求。但这有可能造成客户端拿到陈旧数据(比如其他客户端在另外的 Server 更新了同一 Path)。于是 Zookeeper 设计出了 Sync 操作,会将调用 Sync 时刻的最新提交数据同步到与该 Client 连接的 Server 上,然后将最新数据返回给 Client。即,Zookeeper 将性能与时效性的选择权交给了用户,方法是是否调用 Sync。
一致性视图。Zookeeper 全局会维持一个事务自增标识:zxid,它本质上是个逻辑时钟,可以标识 Zookeeper 一个时刻的数据视图。Client 在故障重启后重新连接到一个新的 Server 时,如果该 Server 未执行到客户端所存 zxid,则要么 Server 执行到该 zxid 后再回复 Client,要么 Client 换一个更新的 Server 进行连接。如此,可以保证 Client 不会看到回退的视图。
会话过期。会话在 Zookeeper 中本质上标识一个 Client 到 Server 的连接。会话有超时时间,如果 Client 长时间(大于超时间隔)不发请求或者心跳,Server 便会删除该会话。
ZooKeeper 协调服务
另一种 ZooKeeper/Chubby 非常适用的场景是选主,对于任务调度器或其他类似有状态服务来说,该功能也十分有用。
另一个例子是,你有一些分了片的资源(数据库、消息流、文件存储、分布式的 actor 等等),并且需要决策哪些分片要放到哪些节点上去。当新节点加入集群后,一些分片需要从现有节点挪动到这些新节点上去,以进行负载均衡。
可以通过谨慎的组合使用 ZooKeeper 中的原子操作、暂态节点和通知机制来实现这类任务。
ZooKeeper,etcd 和 Consul 也会用于服务发现(service discovery)。Actually,相比线性一致性,高可用性和对网络的鲁棒性才是更重要的事情(DNS就不是线性一致的)。尽管服务发现不需要共识协议,但领导者选举需要。
最后更新于