DDIA-数据系统基础
数据系统
如何构建一个好的数据系统,有哪些可以遵循的设计模式?有哪些通常需要考虑的方面?
缓存策略;旁路 or 穿透? 容错:优先可用性还是一致性? 负载扩展?
可靠性
功能上 正常情况下,应用行为满足 API 给出的行为;在用户误输入/误操作时,也能正常处理
性能上 在给定硬件和数据量下,能够满足承诺的性能指标。
安全上 能够阻止未授权、恶意破坏。
可用性也是可靠性的一个侧面。硬件故障、软件错误、人为问题均可能造成错误。系统中最不稳定的因素是人,因此,依据软件的生命周期,在设计层面可分几个阶段来考虑降低人对系统的影响:
设计编码
尽可能消除所有不必要的假设,提供合理的抽象,仔细设计 API
进程间进行隔离,对尤其容易出错的模块使用沙箱机制
对服务依赖进行熔断设计
测试阶段
尽可能引入第三方成员测试,尽量将测试平台自动化
单元测试、集成测试、e2e (端到端)测试、混沌测试
运行阶段 详细的仪表盘、报警机制、问题预案,持续自检
针对组织 科学的培训和管理
可伸缩性
评价系统的能力有两个指标。从客观指标而言,系统负载描述了用户视角的可交互量;而从实际能力考虑,性能更为接近客观事实。
负载
可以用负载参数来衡量负载,比如日活、月活、数据库读写比率、活跃用户数、请求数等。
为应对负载,有两种扩展方式。其中,在多台机器上分配负载也称为无共享体系架构,也结合此引出两种服务类型。
无状态服务 比较简单,多台机器,外层罩一个 gateway 就行。
有状态服务 根据需求场景,如读写负载、存储量级、数据复杂度、响应时间、访问模式,来进行取舍,设计合乎需求的架
弹性负载系统,也就是上云。缺点是抖动、不易跟踪。
书中提到了Twitter对推文的系统设计。根据用户之间的关注与被关注关系来对数据进行多次处理。常见的有推拉两种方式:
拉。每个人查看其首页 Feed 流时,从数据库现拉取所有关注用户推文,合并后呈现。(Lazy, 响应较慢,并发压力)
推。为每个用户保存一个 Feed 流视图,当用户发推文时,将其插入所有关注者 Feed 流视图中。(无效请求多)
性能
衡量指标有:
吞吐量(throughput): 每秒可以处理的单位数据量,通常记为 QPS。
响应时间(response time): 从用户侧观察到的发出请求到收到回复的时间。
延迟(latency):请求过程中排队等休眠时间,其在响应时间中一般占大头。
$response\space time = latency + service\space time$
响应时间通常以百分位点来衡量,比如 p99和 p999,它们意味着99% 或 99.9% 的请求都能在该阈值内完成。在实际中,通常使用滑动窗口滚动计算最近一段时间的响应时间分布,并通常以折线图或者柱状图进行呈现。
可维护性
可维护性(Operability) 将可定义的维护过程编写文档和工具以自动化
简洁性(Simplicity) 找到合适的抽象,并尽量消除各种复杂度。如,层次化抽象。
可演化性(Evolvability) 便于后面需求快速适配:避免耦合过紧,将代码绑定到某种实现上。
数据模型
如何组织数据,如何标准化关系,如何关联现实?
我们有四层叠加模型,通过对外暴露简洁的数据模型,我们隔离和分解了现实世界的复杂度。 如下:
Data Structure
应用开发者将具体问题抽象为一组对象、数据结构,设计合理的API
Data Model
DBA为持久化数据结构,表达为通用的数据模型
Byte
数据库系统开发者将上述数据模型组织为字节流,存储至内存、磁盘及进行网络传输
Signal
硬件工程师使用电位、磁极、光信号表示字节
## 关系模型
在关系模型中,数据被组织成元组(tuples),进而集合成关系(relations)。其特点有:
将数据以关系呈现给用户
提供操作数据集合的算子
常见分类:
事务型(TP):银行交易、火车票
分析型(AP):数据报表、监控表盘
混合型(HTAP)
关系数据库表设计时需要考虑,即如何控制冗余(duplication)。会有几种范式(normalization,面向抽象编程) 来消除冗余。
关系模型很难直观的表示一对多的关系,因此引入文档模型(如,使用 Json 和 XML 的天然嵌套),使其模式灵活、局部性佳、结构表达性好。
文档模型
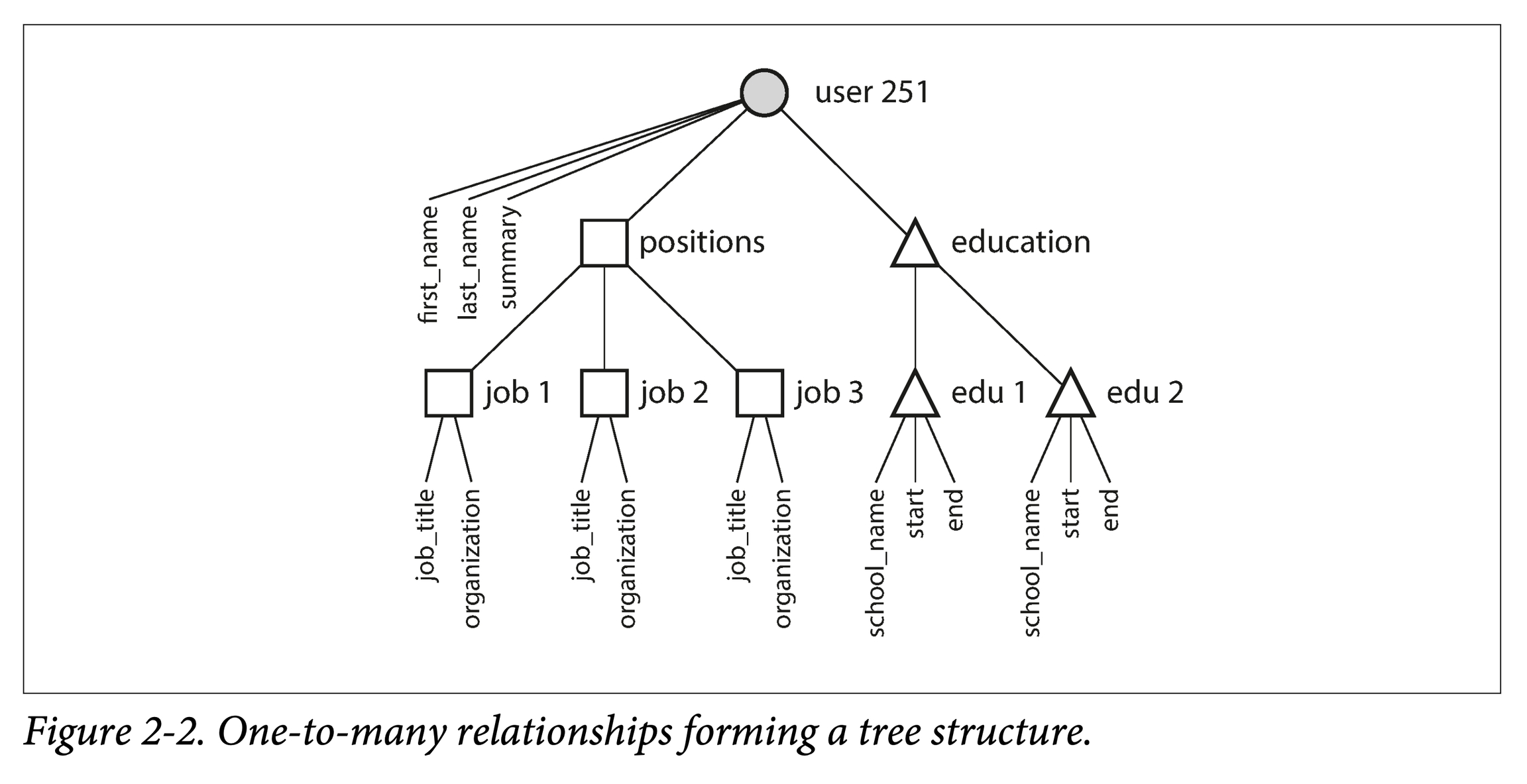
文档型数据库很擅长处理一对多的树形关系,却不擅长处理多对多的图形关系。如果其不支持 Join,则处理多对多关系的复杂度就从数据库侧移动到了应用侧。
模式灵活性:根据校验的时机,可分为schema on read/write 。 数据局部性:针对不同场景,调整数据物理分布以适应常用访问模式的局部性。(HBase使用列族来聚集数据,即参考了此思想)
网络模型,是拓展于树形模型(层次模型)的一种存储模型。以树的方式组织数据,节点存储类型和数据,使用指针进行连接。为支持多对多,访问记录的唯一方式是顺着元素和链接组成的拓扑进行访问,这个链路叫访问路径,需要针对不同应用写大量的专用代码。
图模型
图数据模型的基本概念一般有三个:点,边和附着于两者之上的属性。有多种对图的建模方式:
属性图(property graph):比较主流,如 Neo4j
V(id, out_edges, in_edges, properties)E(id, head_vertex, tail_vertex, label, properties)在E的起点和终点均建立索引,以快速定位顶点的所有入边和出边。三元组(triple-store):如 Datomic
<Subject, Predicate, Object>
图中的点并不局限于同构数据,使用type作为key可以存储异构。
存储与检索
OLTP
请求频繁,单次查询量小
行存储
log-structured/update-in-place
OLAP
对大量数据进行离线(聚合)分析
列存储
ETL(extract-transform-load)
log-structured 的顺序写更快,并发控制简单,碎片少,但是存在空间不紧凑、记录删除(需要引入墓碑机制,待compact回收)、宕机恢复等问题。
数据结构
哈希索引
内存构建哈希索引,K是查询Key,V是记录的起始位置和长度。
适用:key 集合小(能全放内存)、每个 key 更新很频繁、范围筛选查询少。
SSTable
将段文件组织成按键排序的字符串表,即SSTable(sort string table)。其优点有:
合并段时可使用堆排序等增加效率。
不需要维护所有键的偏移,而是稀疏索引。
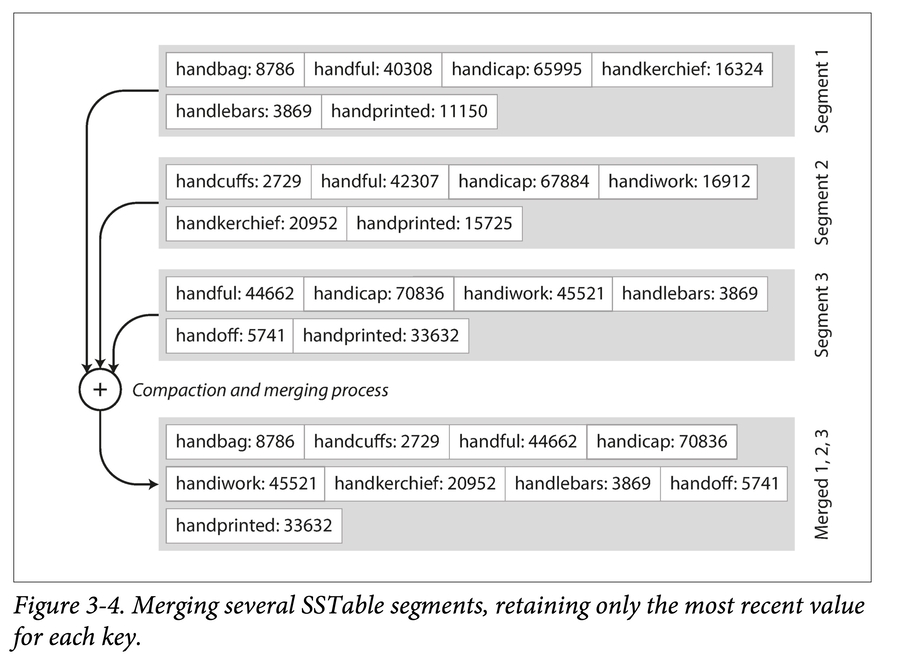
存储引擎的工作流程如下:
在内存中维护一个有序结构(称为 MemTable,如红黑树),到达一定阈值后,作为SSTable 文件 dump 到外存。
后台周期性地执行段合并和压缩,丢弃被覆盖或删除的值。
为每个 SSTable 使用 Bloom Filter 可以在读操作时快速确定一个键是否在某个 SSTable 中,从而减少不必要的磁盘读取。
读请求先在内存表中查找,然后由新到旧搜索磁盘段文件。
LSM-Tree
基于合并和压缩排序文件原理的存储引擎被称为LSM存储引擎,支持高效的点查和范围查。

工业界有一些性能优化:
不存在文件的查询优化:常用 Bloom Filter。该数据结构可以使用较少的内存为每个 SSTable 做一些指纹,起到一些初筛的作用。
大小分级和分层压缩:如共享前缀等。
B-trees
 其特点有: 1. 以*页*(内部读写的最小单元,在磁盘上叫 page,在内存中叫 block,通常为 4k)为单位进行组织。 2. 页之间以页 ID 来进行逻辑引用,从而组织成一颗磁盘上的树。
其特点有: 1. 以*页*(内部读写的最小单元,在磁盘上叫 page,在内存中叫 block,通常为 4k)为单位进行组织。 2. 页之间以页 ID 来进行逻辑引用,从而组织成一颗磁盘上的树。
在树结构的分裂、合并调整时,可能会级联修改很多 Page。在原地更新页上优化:
增加预写日志(WAL),将所有修改操作记录下来,预防宕机时中断树结构调整而产生的混乱现场。或使用COW。
使用 latch(轻量级的锁,锁parent) 对树结构进行并发控制。
对比
就地更新的索引结构(B+Tree)拥有最好的读性能(随机读与顺序读),而随机写性能很差,无法满足现实工业中的工作负载要求。而非就地更新的索引结构-LSM充分发挥顺序写入的高性能特性,成为写入密集的数据系统的基础。
优势
读取更快
写入更快
写放大
1. 数据和 WAL 2. 更改数据时多次覆盖整个 Page
1. 数据和 WAL 2. Compaction
SSD 不能过多擦除。
写吞吐
相对较低: 1. 大量随机写。
相对较高: 1. 较低的写放大(取决于数据和配置) 2. 顺序写入。 3. 更为紧凑。
压缩率
1. 存在较多内部碎片。
1. 更加紧凑,没有内部碎片。 2. 压缩潜力更大(共享前缀)。
compact不及时会造成很多垃圾
后台流量
1. 更稳定可预测,不会受后台 compaction 突发流量影响。
1. 写吞吐过高,compaction 跟不上,会进一步加重读放大。 2. 由于外存总带宽有限,compaction 会影响读写吞吐。 3. 随着数据越来越多,compaction 对正常写影响越来越大。
写入太快可能引起 write stall,限制写入,以期尽快 compaction 将数据下沉。
存储放大
1. 有些 Page 没有用满
1. 同一个 Key 存多遍
并发控制
1. 同一个 Key 只存在一个地方 2. 树结构容易加范围锁。
同一个 Key 会存多遍,一般使用 MVCC 进行控制。
索引结构
数据本身无序的存在文件中,称为 堆文件(heap file),索引的值指向对应数据在 heap file 中的位置。这样可以避免多个索引时的数据拷贝。
数据本身按某个字段有序存储,该字段通常是主键。则称基于此字段的索引为聚集索引(clustered index,将索引和数据存在一块)。基于其他字段的索引为非聚集索引,在索引中仅存数据的引用(位置)。
一部分列内嵌到索引中存储,一部分列数据额外存储,称为覆盖索引(covering index)
对多列联合建立索引,称为嵌套索引(Multi-Column index)
数据仓库
星型模式和雪花型模式
星型模式(维度建模):包含一张事件表(fact table) 和多张维度表(dimension tables)。事件表以事件流的方式将数据组织起来,然后通过外键指向不同的维度。 雪花模型:精细化的维度建模,可以类比雪花(❄️)图案。其特点是在维度表中会进一步进行二次细分,讲一个维度分解为几个子维度。
列存储压缩
如果每一列中值阈相比行数要小的多,可以用位图编码。 如果 bit array 是稀疏的,即大量的都是 0,只有少量的 1,还可以使用 游程编码(RLE, Run-length encoding) 进一步压缩。

列存储写入
数仓查询多集中于聚合算子(比如 sum,avg,min,max),列式存储中的存储顺序相对不重要,因为不影响聚合结果。
不可能同时对多列进行排序。因为我们需要维护多列间的下标间的对应关系,才可能按行取数据。
在分布式数据库(数仓这么大,通常是分布式的)中,同一份数据我们会存储多份。对于每一份数据,我们可以按不同列有序存储。这样,针对不同的查询需求,便可以路由到不同的副本上做处理。
对于写入的处理,使用LSM模式,因为update-in-place开销太大了。
聚合:物化视图
物化聚合,也称为持久化聚合,其实就是将聚合函数的执行结果事先缓存起来,是一种用空间换时间的方案。比如下图: 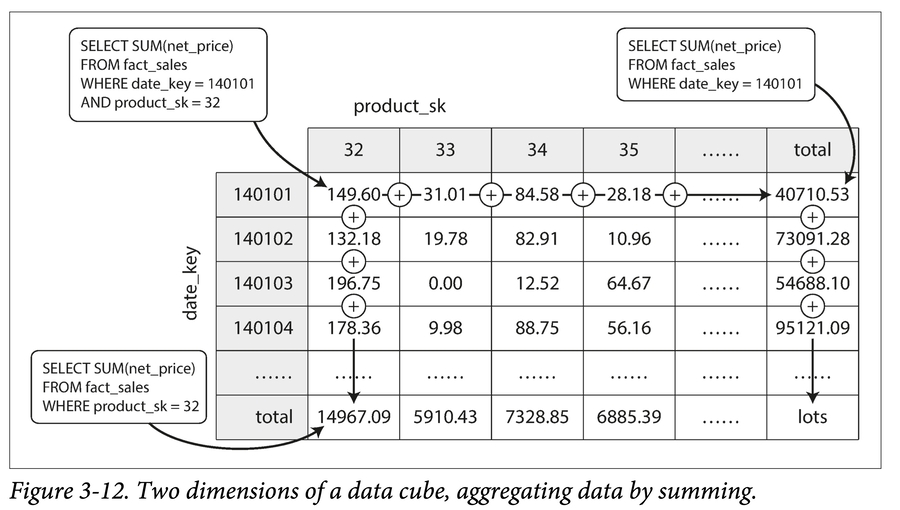
编码
将数据写入文件或通过网络发送时,由于指针对其他进程并无意义等,故需要将其编码(序列化) 成自包含的字节序列。
向后兼容 (backward compatibility) 当前代码可以读取旧版本代码写入的数据。 向前兼容(forward compatibility) 当前代码可以读取未来版本代码写入的数据。
使用语言内置的序列化包通常不是个好主意,因为其耦合于特定的语言,兼容性差, 且存在安全问题。
文本编码
JSON,XML 和 CSV 属于常用的文本编码格式,其好处在于肉眼可读,坏处在于:
不够紧凑,占空间较多。
对二进制数据支持不够(可以通过 Base64 编码绕过,但混乱且费33%的空间)
CSV没有模式
二进制编码
MessagePack
使用(类型)长度, bit 串顺序编码,去掉无用的冒号、引号、花括号。
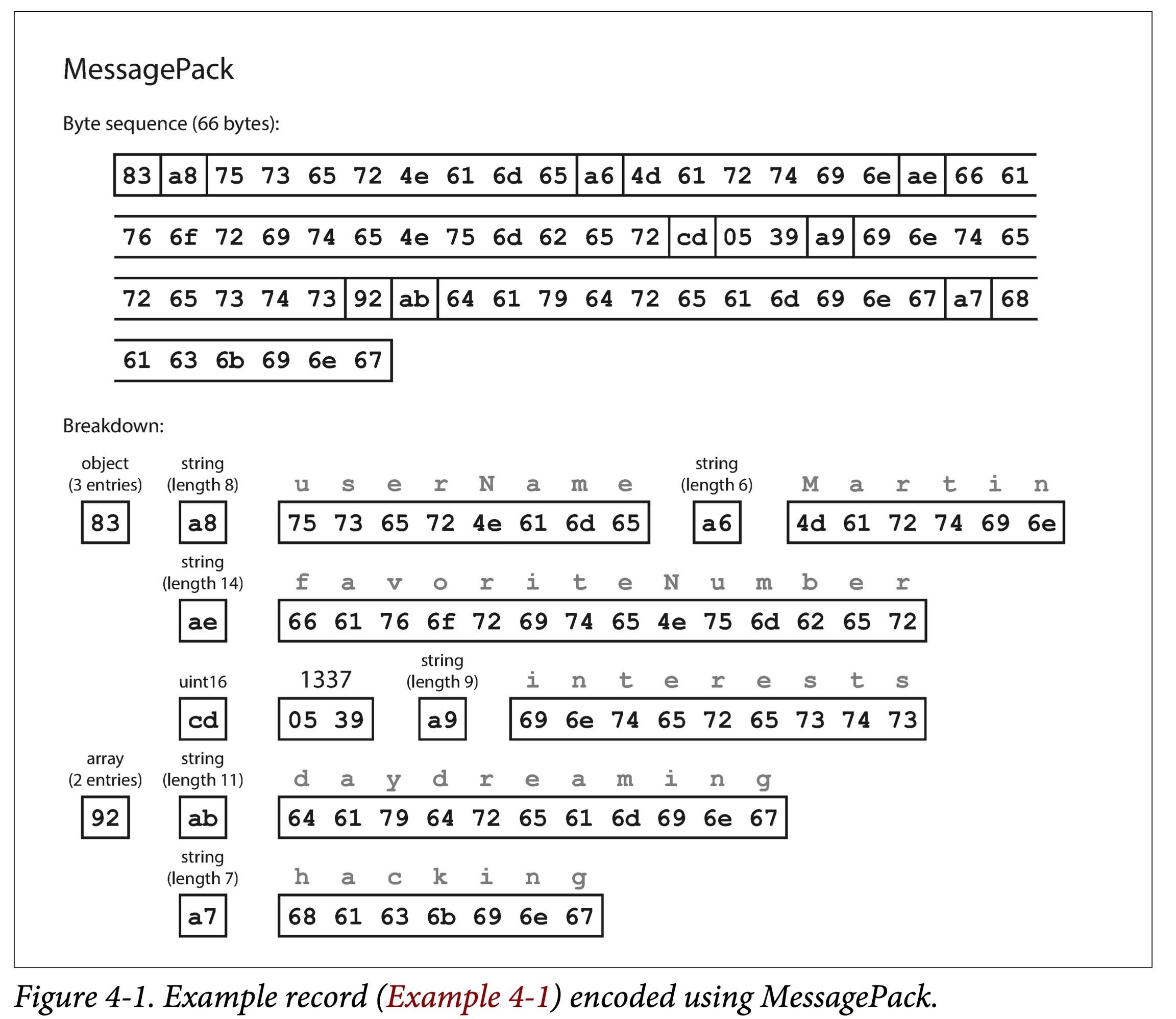
压缩率不高。
Thrift 和 Protocol Buffers
在编码前都需要由接口定义语言(IDL)来描述模式(与编程语言无关)。如:
Thrift
 还有CompactProtocol 变种,将字段类型和标签号偏移量 打包到一个byte中,使用可变长整数实现。 2. Protobuf
还有CompactProtocol 变种,将字段类型和标签号偏移量 打包到一个byte中,使用可变长整数实现。 2. Protobuf 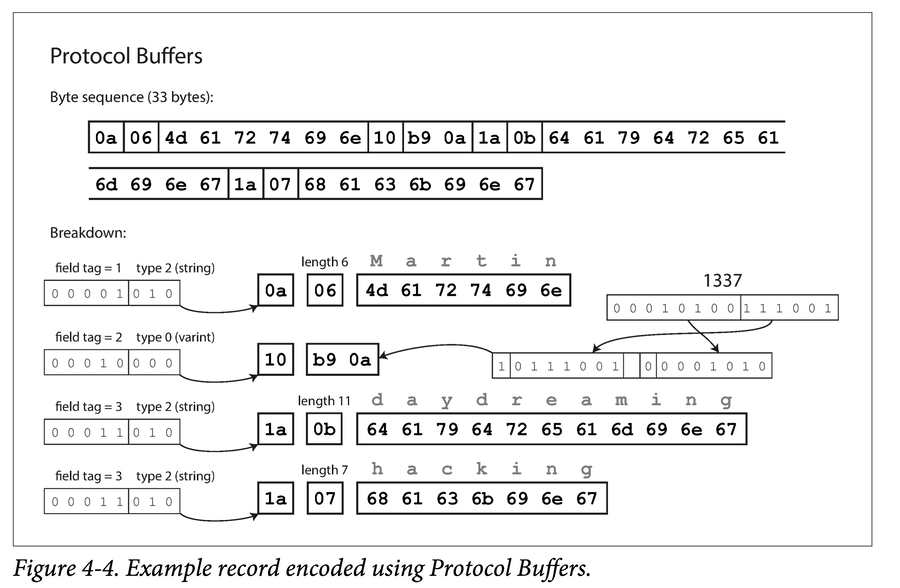
通过数据类型的注释通知解析器跳过特定字节数,可以实现向前兼容性。 只要每个字段对应一个唯一的标签号,则具有向后兼容性。
Avro
Avro 必须配合模式定义来解析,如 Client-Server 在通信的握手阶段会先交换数据模式。
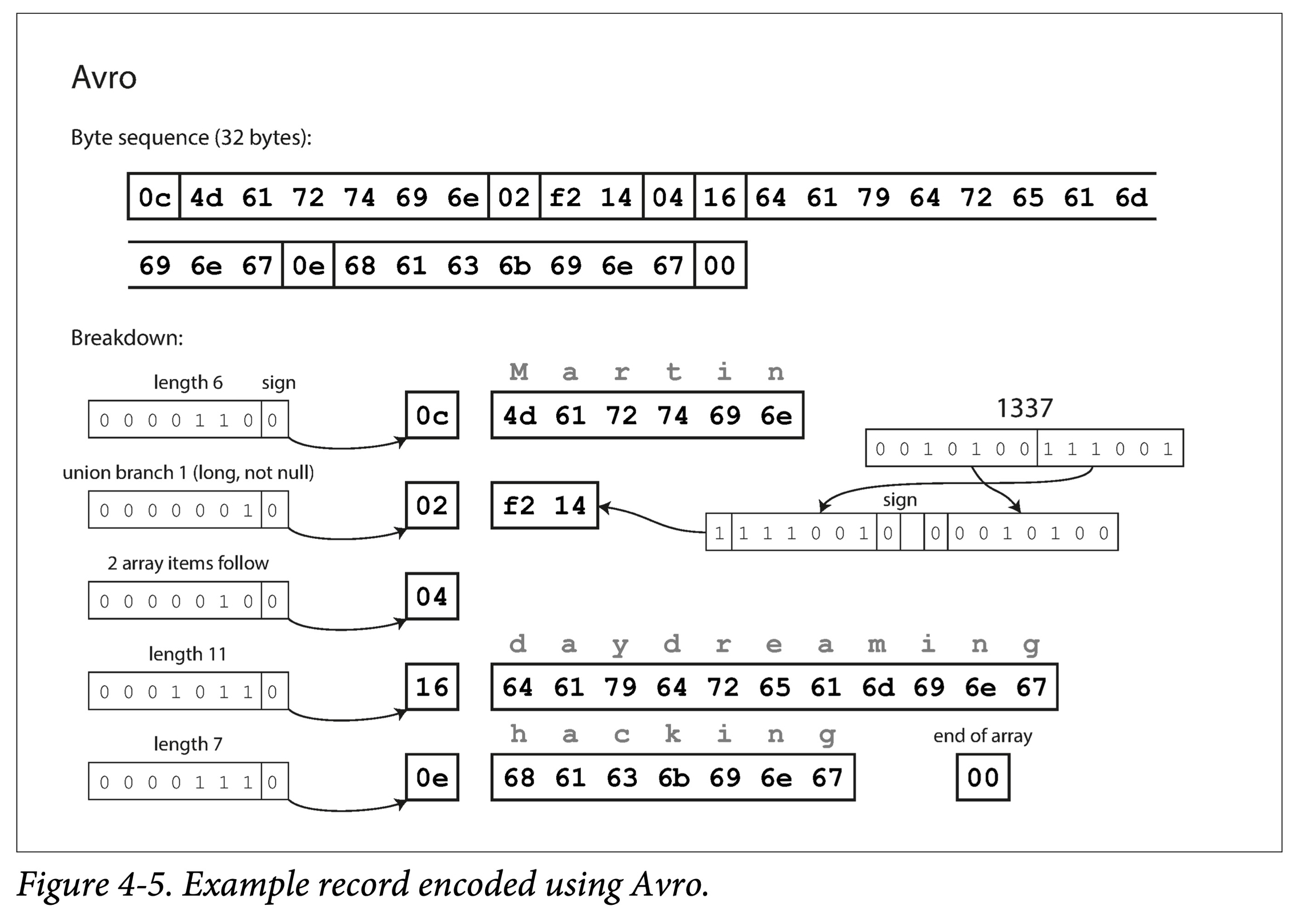
数据模式分为读模式和写模式,可以将模式写入数据文件, Avro 可动态解析之。在对数据进行编码(写入文件或者进行传输)时,使用写模式(writer schema);在对数据进行解码(从文件或者网络读取)时,使用读模式(reader schema),而两者不必相同,只需兼容。
匹配规则为 :使用字段名(无关顺序)、忽略多余字段、对缺失字段赋予默认值。
向后兼容:读取时首先得到旧数据的写模式(即旧模式),然后将其与读模式(即新模式)对比,得到转换映射,再解析旧数据。 向前兼容:类似,需要得到一个逆向映射。
Avro对动态生成的模式更为友好,不需要手动维护字段标号到字段名的映射,只需要在导出时依据当时的模式,做相应的转换,生成相应的模式数据即可,不需要手动分配字段标签。
数据流
服务
当服务使用 HTTP 作为通信协议时,我们通常将其称为 web 服务。一般是暴露在公网的服务。
REST(Representational State Transfer)是一种基于HTTP原则的设计理念。使用URL来标识资源,并使用HTTP进行缓存控制、身份验证、内容类型协商。 RESTful的API倾向于简单的方法,定义格式如OpenAPI(也称为Swagger),可用于描述RESTful API并生成文档,涉及较少的代码生成和自动化工具。
服务器也可以同时是客户端访问其他服务。可以使用RPC。需要注意一些问题:
网络请求是异步的,其返回是不确定的
对于较大的对象,本地的指针访问转换成字节序列时可能会出现问题
考虑重试的幂等性问题
语言兼容性问题。如JavaScript的$2^{53}$ 。
消息
消息队列的逻辑抽象叫做 Queue 或者 Topic,常用的消费方式两种:
多个消费者互斥消费一个 Topic
每个消费者独占一个 Topic
消息队列通常是面向字节数组的,因此你可以将消息按任意格式进行编码。如果编码是前后向兼容的,同一个主题的消息格式,便可以进行灵活演进。
分布式的 Actor 框架
Actor 模型是一种基于消息传递的并发编程模型。三部分组成:
状态(State):Actor 中包含的状态信息。
行为(Behavior):Actor 中对状态的计算逻辑。
信箱(Mailbox):Actor 接受到的消息缓存地。可以理解为MQ
由于 Actor 和外界交互都是通过消息,因此本身可以并行的,且不需要加锁。
参考: https://ddia.qtmuniao.com/
最后更新于
这有帮助吗?