计算机底层知识
Introduction
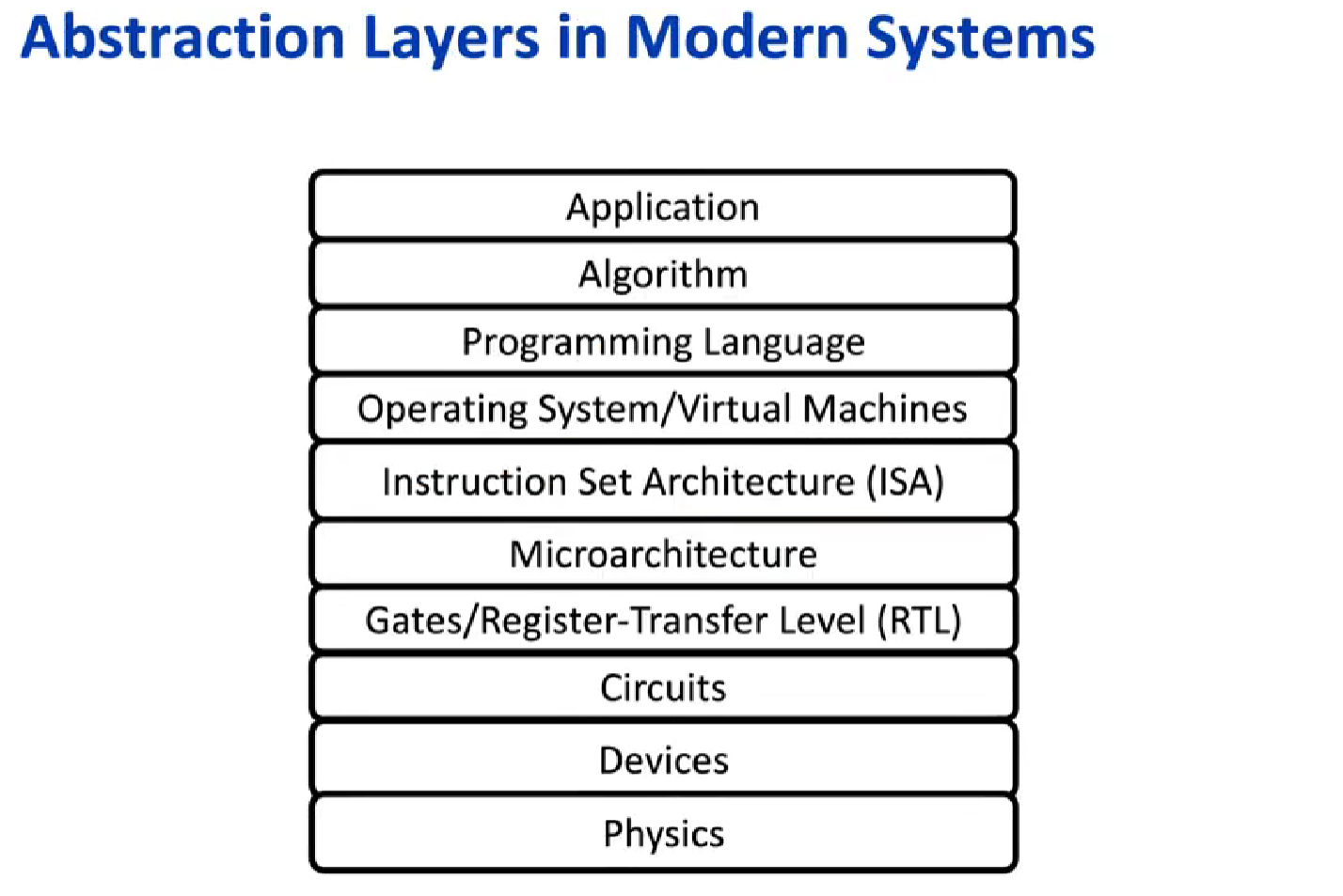
ISA相当于软件和硬件之间的界线
Why Architecture?
First, the virtual elimination of assembly language programming reduced the need for object-code compatibility.
the creation of standardized, vendor-independent operating systems, such as UNIX and its clone, Linux, lowered the cost and risk of bringing out a new architecture. 体系结构涵盖了计算机设计的所有 3 个方面:指令集体系结构、组成或微体系结构、硬件 。
RISC
instruction-level parallelism (pipelining -> multiple instruction issue)
caches (more sophisticated organizations and optimizations).
并行度
多种级别的并行度已经成为计算机设计的驱动力。
应用程序中主要有以下两种并行:
数据级并行(DLP):有许多数据项可以同时操作。
任务级并行(TLP):创建的工作任务可以单独执行并且主要采用并行方式执行。
计算机硬件又以如下4种主要方式来利用这两种类型的应用并行:
指令级并行。 在两个层面对数据级并行进行了利用,首先在编译器的帮助下,借助流水线之类的思想适度利用;其次借助推测执行(speculative execution)之类的思想进一步利用。
向量体系结构、图形处理器(graphic processor unit,GPU)和多媒体指令集(multimedia instruction set) 将单条指令并行应用于一组数据,以利用数据级并行。
线程级并行。在一种紧藕合硬件模型中利用数据级并行或任务级并行,这种模型允许并行线程之间进行交互。
请求级并行。利用程序员或操作系统指定的大量解耦任务之间的并行性。
对于并行计算的工作量,可分为四类计算机:SISD(单指令流单数据流)、SIMD(同一指令由多个使用不同数据流的处理器执行)、MISD、MIMD(每个处 理器都提取自己的指令,对自己的数据进行操作,它针对的是任务级并行)。
许多并行处理器其实是 SISD 、SIMD 和 MIMD 的混合类型 。
性能测试
随着互联网服务的普及,有更多的方式来判断一个系统的运行是否正常。基础设施供应商开始提供服务等级协议(service level agreement, SLA )或服务等 级目标(service level objective, SLO ) ,以保证他们的网络或电源服务是可靠的。
系统在 SLA 规定的两种服务状态之间切换:
服务完成,即提供了指定服务。
服务中断,即所提供的服务与 SLA 不一致 。
在报告性能测试结果时,应遵循一条指导原则——可再现性。
计算机设计的量化原理
充分利用并行
系统级别利用并行:可以使用多个处理器和多个存储设备,分散请求,提高吞吐量。扩展内存以及增加处理器和存储设备数目的能力称为可扩展性。
单个处理器级别:充分利用指令间的并行对实现高性能非常关键。实现这种并行的一种最简单的方法就是流水线(将指令执行重叠起来,以缩短完成指令序列的总时间)。
数字设计级别:组相联(set-associative) 缓存使用多体存储器,通常可以对它们进行并行查询,以查找所需项。
局部性原理
时间局部性(temporal locality) :最近访问过的内容很可能会在短期内被再次访问。 空间局部性(spatial locality) :地址相邻近的项往往会在相近的时间被用到。
重点关注常见情形:Amdahl 定律
Amdahl 定律表明,使用某种快速执行模式获得的性能改进受限于可使用此种模式的时间比例。可以计算出通过改进计算机某一部分而获得的性能增益。
Amdahl 定律定义了使用特定功能可获得的加速比 (speedup),即改进前 后 的性能(执行时间)之比。取决于原计算机计算时间中可改进部分所占的比例(改进比例 )和使用这一执行模式时,任务的运行速度会提高多少倍(改进加速比)
存储器层次结构
基础知识
======= 从计算机体系结构的角度看,存储系统是分为多个层级的。从上到下依次可以分为:寄存器、高速缓存(Cache)、主存储器、辅助存储器。设计这种分层的存储结构,就可以充分利用不同存储设备的优点,规避缺点,在存储速度、存储容量、成本三方面取得一个平衡点。
现代CPU引入了3级缓存,结构如下图所示:
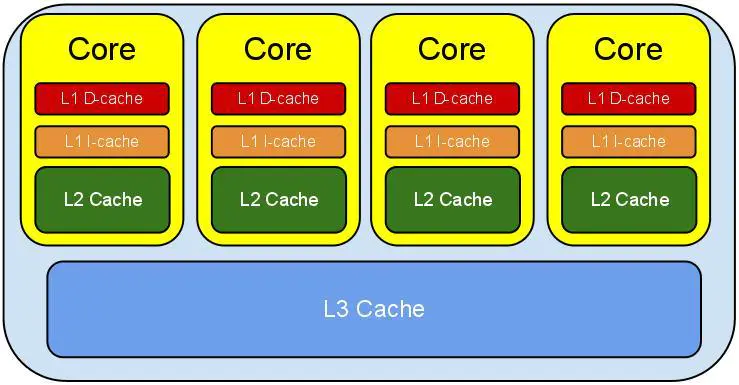
越靠近CPU的缓存容量越小但是速度越快,这也是存储速度、存储容量、成本三个方面平衡的一种体现。
L1 Cache分为D-Cache和I-Cache,D-Cache用来存储数据,I-Cache用来存放指令,一般L1 Cache的大小是32KL2 Cache更大一些,例如256K,速度要慢一些,一般情况下每个核上都有一个独立的L2 CacheL3 Cache是三级缓存中最大的一级,同时也是最大的一级,在同一个CPU插槽之间的核共享一个L3 Cache。
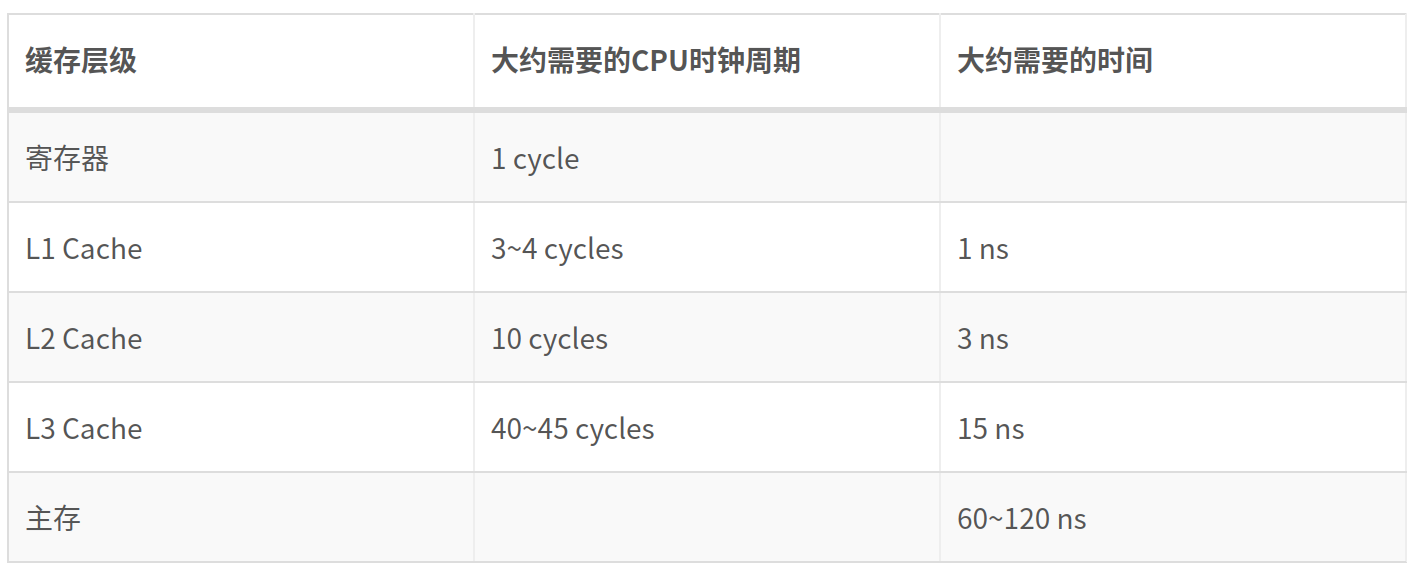
下面的列表展示了CPU读取各级缓存的时间:
基础知识
缓存的多端口和流水线:利用三级缓存,即每个核使用两个级别的私有缓存,以及一个共享的 L3 缓存;在第一级使用独立的指令与数据缓存。
缓存中找不到某一个字,就必须从层次结构较低的一个层级(可能是另一个缓存,也可能是主存储器)中提取相关的多个字(块,也称行)。也就是为了提高缓存命中率,CPU读取数据并不是以单个数据为单位读取的,而是一次读取一块数据到缓存中。这样读取的一块数据被保存在缓存行(Cache Line,在下文和块混用)中。 这样每次读取数据就把周围的数据也一起读到缓存中,根据程序的空间局部性原理,这样做可以显著提高数据中命中率。
块在缓存中的组织方式:最常见的方案是组相联(set associative) ,其中组是指缓存中的一组块。一个块首先被映射到一个组上,然后可以将这个块放到这个组中的任意位置。要查找一个块,首先要将这个块的地址映射到这个组,然后再搜索这个组(通常为并行搜索)。
提高相联度可以减少冲突缺失,以延长命中时间为代价。
如果组中有 n 个块,则缓存的布局被称为 n 路组相联 (n-way set associative)。 组相联的端点有其自己的名字。
直接映射缓存(direct-mapped cache) 的每组中只有一个块(所以块总是放在同一个位置) 。
全相联缓存(fully associative cache) 只有一个组(所以块可以放在任何地方)。
缓存副本和存储器怎样才能保持一致呢?主要有两种策略:
写直达(write-through, 写穿透):更新缓存中的条目时,会同时将数据写入主存储器中,并对其进行更新。
写回(write-back):仅更新缓存中的副本。在要替换这个块时,再将它复制回存储器。
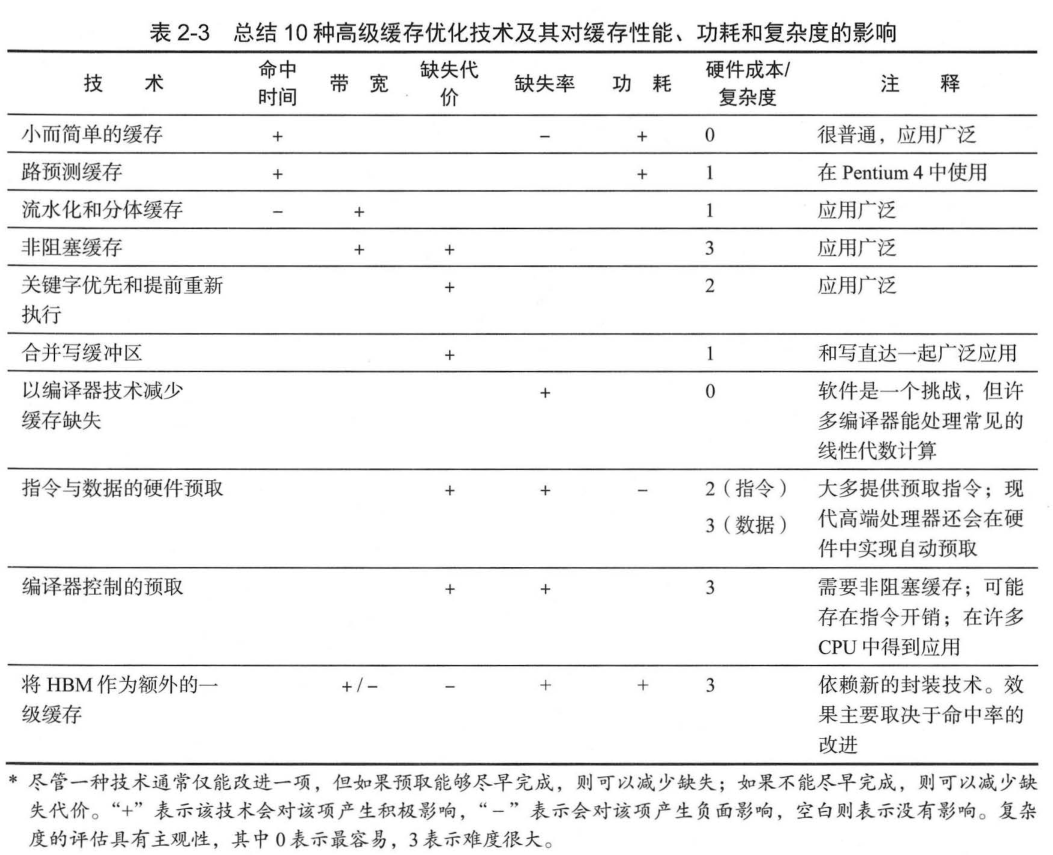
图中: 多体缓存,就是实现在每个时钟周期内进行多次访问,从而提高缓存的带宽。这些优化方法主要面向 L1(代价是会增加延迟), 这里的访问带宽限制了指令吞吐率。L2 和 L3 缓存中也会使用多个存储体,但主要功耗管理。 非阻塞缓存 (nonblocking cache,或称 无锁缓存 lockup-free cache) 允许数据缓存在一次缺失期间继续提供缓存命中——如果能够重叠多个缺失,缓存就能进一步降低实际的缺失代价 。
页式虚拟存储器(包括缓存页表条目的 TLB) 是避免进程相互影响的主要机制。
伪共享
因为缓存行(块)的存在,在多核处理器上会发生较为隐蔽的伪共享,如访问一个类的连续两个字段变量:一个运行在处理器core1上的线程想要更新变量x,同时另外一个运行在处理器core2上的线程想要更新变量y。两个变量由于处于同一个缓存行的话,线程对一个变量的修改会导致整行的数据失效,另外一个线程不得不从L3 Cache中重新加载数据。看起来两个线程是在互不影响地操作两个变量,但是因为它们共享了一个缓存行,因此两个线程会发生激烈的冲突。
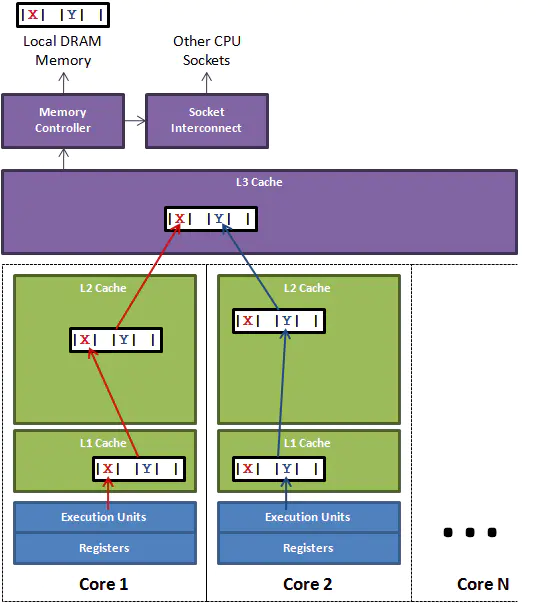
如何避免伪共享呢?一种方法是缓存行填充(Padding)。我们只需要在x和y变量之间填充若干long类型的变量,让x和y变量处于不同的缓存行,就避免了伪共享。Java8中还提供了@sun.misc.Contended注解,JVM会在使用此注解的对象或者变量前后各增加128字节大小的padding,使用2倍于大多数硬件缓存行大小的填充来避免伪共享冲突。
最后更新于