系统中间件
Scalability
Load Balancer
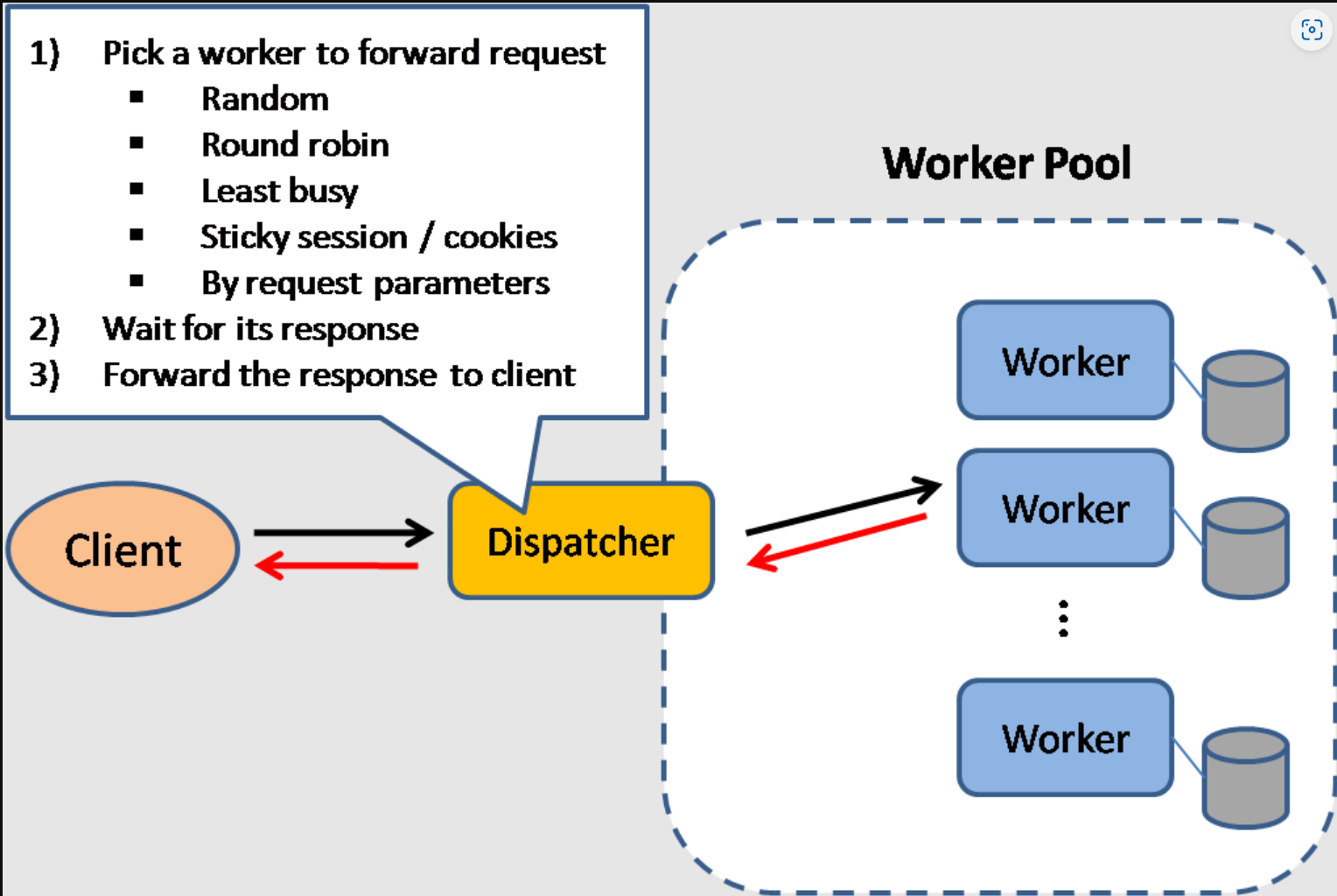
负载均衡方法有以下。nginx 支持以下负载均衡方法已加黑。
随机 random:将 key 随机分配到某一个 slot 上,根据概率论可知,吞吐量越大,随机算法的效果越好;
加权随机 weighted random:为每一个 slot 分配一个权重,在随机的时候考虑权重的影响;可以通过在所有 slot 的权重总和中随机出一个数字 k,找到 k 所在的 slot 位置来实现;
轮询 round robin: DNS return IP one by one, i.e. S1, S2, S3, S1, S2... nginx默认;
加权轮询 weighted round robin:为每一个 slot 分配一个权重,在按序分配时为权重更高的 slot 分配更多的 key;
平滑加权轮询 smooth weighted round robin:一种能够均匀地分散调度序列的加权轮询方法,分为以下几个步骤:
选出当前权重最高的 slot,将 key 分配给它;
将选出的 slot 的权重数值减去其初始权重;
将所有 slot 的权重数值都加上它们的原始权重;
重复以上步骤
最少连接数 least connections:将 key 分配给当前具有最少连接数量的 slot;
ip 哈希(ip-hash) - 使用哈希函数确定下一个请求应该选择哪一个服务器(基于客户端的 IP 地址)
分类:
四层负载均衡:根据传输层的头部(如协议和应用程序端口)管理流量,来决定如何分发请求。(执行网络地址转换(NAT))无需查看消息的实际内容。
七层负载均衡:根据监控应用层来决定怎样分发请求,根据更详细的信息(例如 HTTP/HTTPS 标头的特征、消息内容、URL 类型和 cookie 数据)做出路由决策。(灵活)
That is the sharding. Servers may partioning(分流)and replicating(备份)
Need to have a RAID server to store sessions? Or, we can store the address of the server in the cookie but private IP is visiable to the whole world! --> Store a random number and let the load balancer remember which number belongs to which server.
负载均衡器可以通过硬件(昂贵)或 HAProxy 等软件来实现。 增加的好处包括:
SSL 终结 - 解密传入的请求并加密服务器响应,这样的话后端服务器就不必再执行这些潜在高消耗运算了。
不需要在每台服务器上安装 X.509 证书。
Session 留存 - 如果 Web 应用程序不追踪会话,发出 cookie 并将特定客户端的请求路由到同一实例。
Server-side consistency: N(replica nodes) < W(receipt of update required before change) + R(access replicas in read contact) is strong!
反向代理
 来自客户端的请求先被反向代理服务器转发 到可响应请求的服务器,然后代理再把服务器的响应结果返回给客户端。可以集中地调用内部服务,并提供统一接口。牺牲一定的复杂度,带来以下优势:
来自客户端的请求先被反向代理服务器转发 到可响应请求的服务器,然后代理再把服务器的响应结果返回给客户端。可以集中地调用内部服务,并提供统一接口。牺牲一定的复杂度,带来以下优势:
增加安全性 - 隐藏后端服务器的信息,屏蔽黑名单中的 IP,限制每个客户端的连接数。
提高可扩展性和灵活性 - 客户端只能看到反向代理服务器的 IP,这使你可以增减服务器或者修改它们的配置。
SSL 终结
压缩 - 压缩服务器响应包体
缓存 - 直接返回命中的缓存结果
静态内容 - 直接提供静态内容(HTML/CSS/JS、图片、视频等)
Database Replication
Master-Slave:R in slaves and RW in master Master-Master:all nodes RW and sync Tree-Replication:combine masters and slaves as tree Buddy:B replice to C and is A's backup.
for easy to migrate, You can stay with MySQL, and use it like a NoSQL database, or you can switch to a better and easier to scale NoSQL database like MongoDB. You will need to introduce a cache.
Cache Pattern
We recommend Cached Objects,Assemble the data in the database as the complete instance of a class as cache.
And so makes async-processing available.
Trade-offs
性能与可扩展性
延迟与吞吐量
可用性与一致性
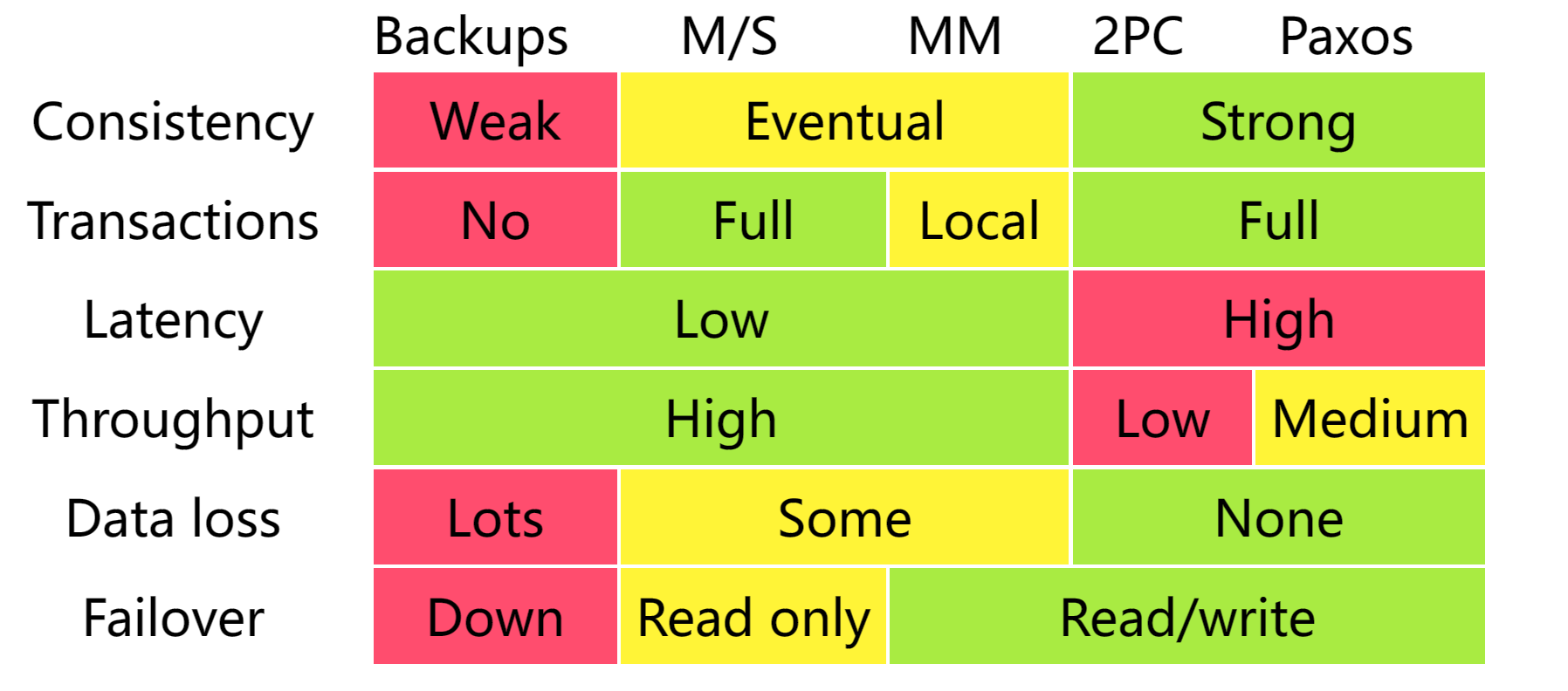
文件描述符在多核处理器上,性能从读L1缓存到L3缓存间传递 进程间通信速度比函数调用慢16倍
Concurrency
Share-state: use lock to prevent data race
Message-Passing: async
Publish/Subscribe
Point2Point
Store-Forward
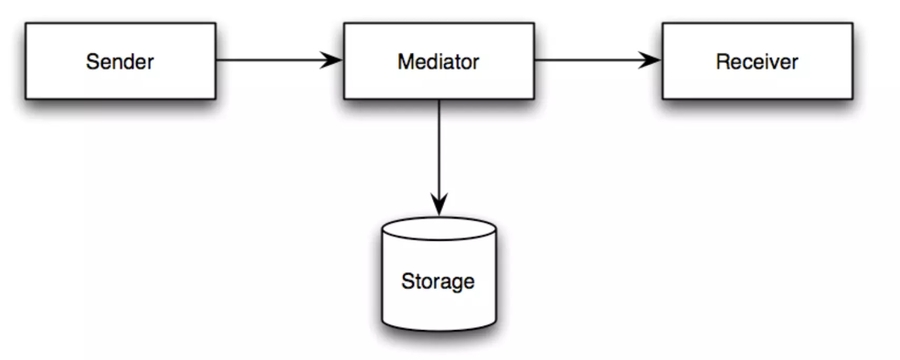
Request-Reply
DataFlow: Data blocked until ready
Transactional Memory:idempotent scope required.
应用层
微服务
微服务可以被描述为一系列可以独立部署 的小型的,模块化服务。在运行时,每个实例通常是一个云虚拟机(VM)或者一个 Docker 容器。通过明确定义的轻量级机制通讯(每个后端服务暴露一个 REST API),共同实现业务目标。
单体应用难以扩展。如:CPU 密集型图像处理逻辑模块,理想情况是部署在计算优化中;而内存数据库模块,更适合部署到内存优化实例中。如果耦合部署在一起,则必须在硬件选择上做出妥协。因此引入微服务,不过需要处理好分布式系统的问题。
进程间通信
C/S交互方式:根据每个客户端请求被一个或多个服务实例处理,分为两类:一对一 和 一对多。根据同步和异步,可以分为: 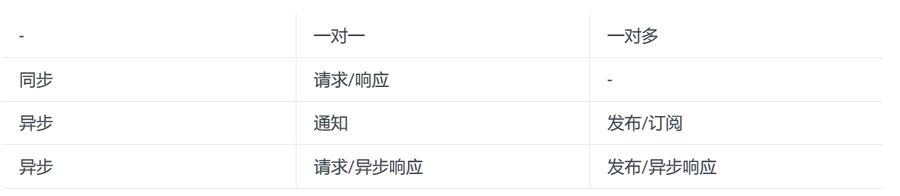
为处理局部故障,可以引入断路器模式 :追踪成功和失败请求的数量。如果错误率超过配置阈值,则断开断路器,以使后续的尝试能立即失败。如果出现大量请求失败,则表明服务不可用,发送请求将毫无意义。发生超时后,客户端应重新尝试,如果成功,则关闭断路器。
服务发现
API 网关需要知道与其通信的每个微服务的网络位置(IP 地址和端口)。在传统应用中,你可以将这些静态位置硬编码,而在现代基于云的微服务应用中,找到动态的位置需要使用更精确的服务发现机制。像 Consul,Etcd 和 Zookeeper 这样的系统可以通过追踪注册名、地址、端口等信息来帮助服务互相发现对方。Health checks 可以帮助确认服务的完整性和是否经常使用一个 HTTP 路径。Consul 和 Etcd 都有一个内建的 key-value 存储 用来存储配置信息和其他的共享信息。
客户端发现模式:查询服务注册中心,利用负载均衡算法选择一个可用的服务实例并发出请求。
服务端发现模式:由
router查注册中心,服务器间处理服务发现。
服务注册中心使用了复制协议(replication protocol)来维护一致性的服务器集群组成。服务实例必须在服务注册中心中注册与注销。有几种不同的方式来处理注册和注销。一是服务实例自我注册,即自注册模式。另一个是使用其他系统组件(服务注册器)来管理服务实例的注册,即第三方注册模式。
重构
停止挖掘:将新代码放到独立的微服务中。
前后端分离:从业务逻辑层(BLL,实现业务规则的组件)和数据访问层(DAL,数据访问基础设施组件,如数据库和消息代理)拆分出表现层(PL,处理 HTTP 请求并实现(REST)API 或基于 HTML 的 Web UI 组件)。
提取服务
远程过程调用协议(RPC)
RPC 是一个“请求-响应”协议:
客户端程序 ─ 调用客户端存根程序。就像调用本地方法一样,参数会被压入栈中。
客户端 stub 程序 ─ 将请求过程的 id 和参数打包进请求信息中。
客户端通信模块 ─ 将信息从客户端发送至服务端。
服务端通信模块 ─ 将接受的包传给服务端存根程序。
服务端 stub 程序 ─ 将结果解包,依据过程 id 调用服务端方法并将参数传递过去。
RESTful 接口设计
RESTful 接口有四条规则:
标志资源(HTTP 里的 URI) ─ 无论什么操作都使用同一个 URI。
表示的改变(HTTP 的动作) ─ 使用动作, headers 和 body。
可自我描述的错误信息(HTTP 中的 status code) ─ 使用状态码,不要重新造轮子。
HATEOAS(HTTP 中的HTML 接口) ─ 你的 web 服务器应该能够通过浏览器访问。
SpringBootProject中有RESTful成熟度层次,可查阅。
数据访问层
关系型数据库管理系统(RDBMS)
关系型数据库扩展包括许多技术:
主从复制
主主复制:多数主-主系统要么不能保证一致性(违反 ACID),要么因为同步产生了写入延迟,如何解决冲突显得越发重要。
联合:将数据库按对应功能分割。
分片:将数据分配在不同的数据库上,使得每个数据库仅管理整个数据集的一个子集。
非规范化:以写入性能为代价来换取读取性能。在多个表中冗余 数据副本,以避免高成本的联结操作、减少了外部键和索引的限制。
SQL调优:利用基准测试和性能分析来模拟和发现系统瓶颈。
缓存
缓存可以位于客户端(操作系统或者浏览器),服务端或者不同的缓存层。如:CDN被视为一种缓存、Web 服务器反向代理作为缓存、应用缓存。
直写
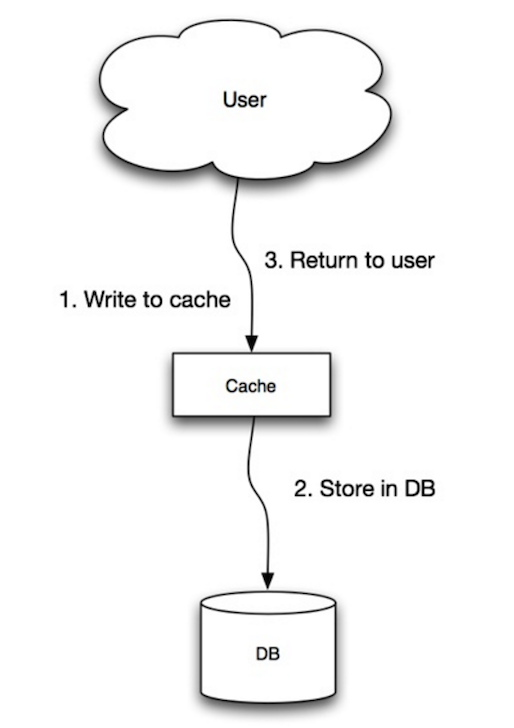
由于故障或者缩放而创建的新的节点,新的节点不会缓存,直到数据库更新为止。缓存应用直写模式可以缓解这个问题。 写入的大多数数据可能永远都不会被读取,用 TTL 可以最小化这种情况的出现。
回写
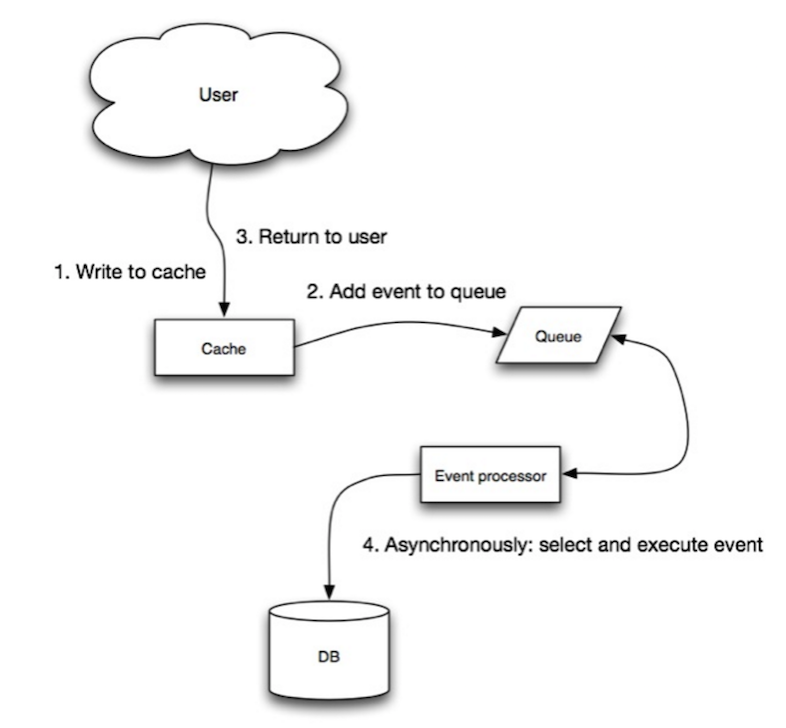
异步写入数据,提高写入性能;缓存可能在其内容成功存储之前丢失数据
#### Read/Write Through策略
读穿 / 写穿策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互,相当于更新数据库的操作由缓存自己代理了。 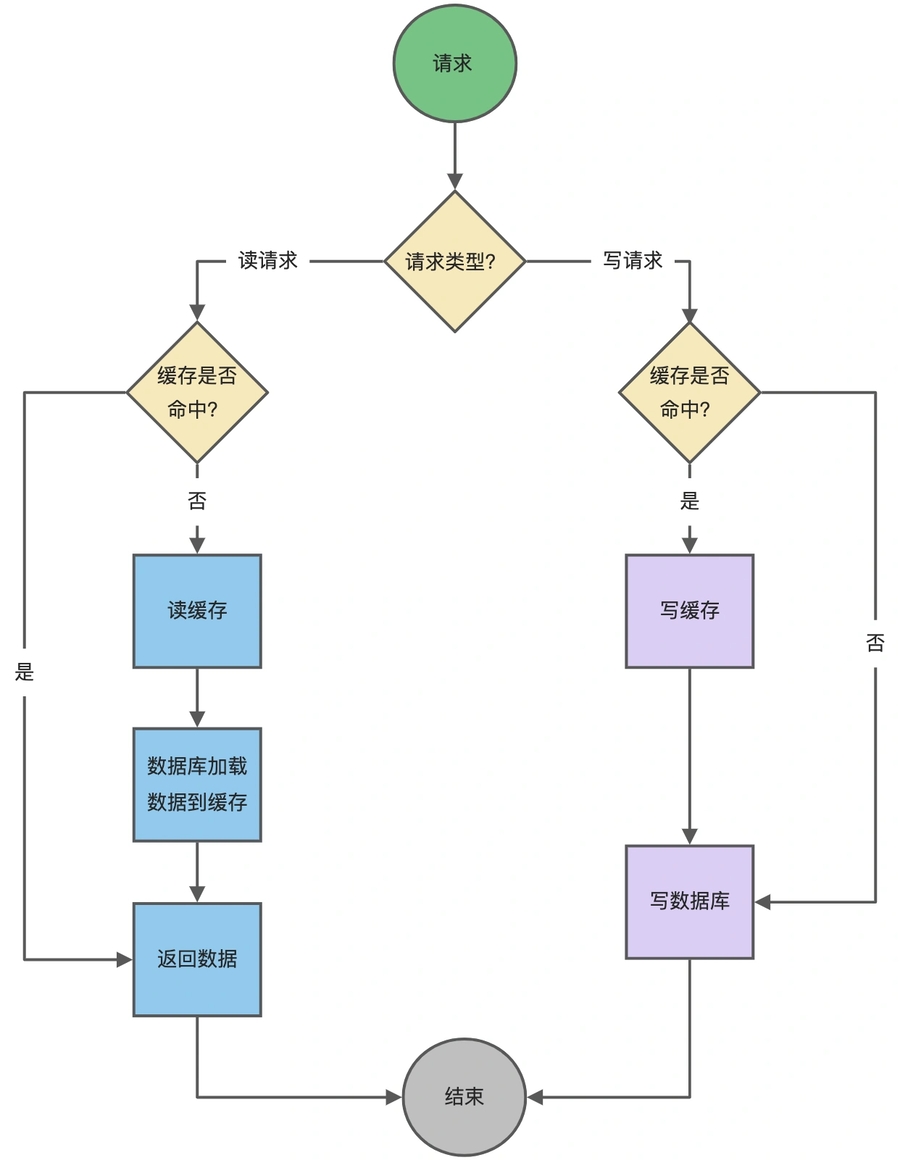
Cache Aside 策略
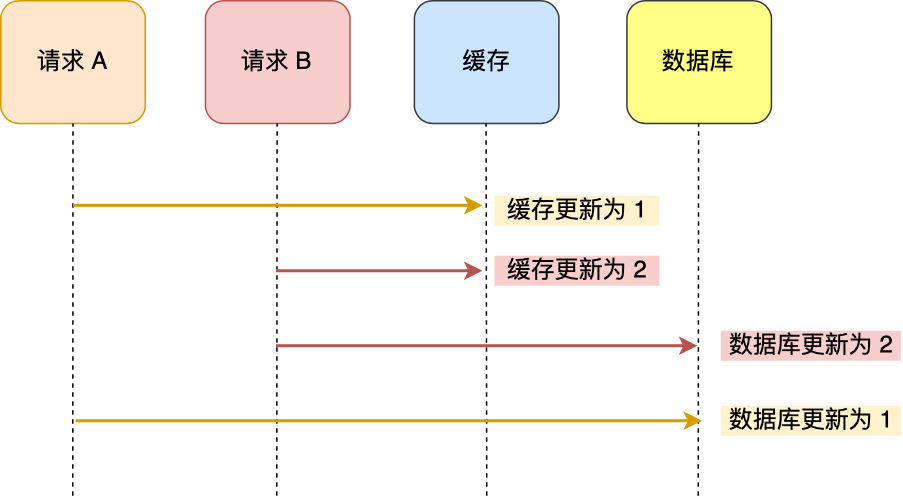
适合读多写少的场景。 并发问题:当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象。需要引入分布式锁或对缓存加入非常短的过期时间(要求忍受延迟)
旁路缓存策略细分为读策略和写策略。
写策略:更新数据库中的数据;删除缓存数据。
读策略:数据命中了缓存,则直接返回数据;没有命中则从数据库中读取数据,然后将数据写入到缓存,并且返回给用户。
写策略可以先删除缓存吗?
不能。需要引入延迟双删。即,先删除缓存、更新数据库后,睡眠一段时间再次删除缓存。通过这段睡眠时间的配置,完成从数据库读取数据 + 写入缓存。 因为缓存的写入通常要远远快于数据库的写入,所以在实际中很难出现请求 B 已经更新了数据库并且删除了缓存,请求 A 才更新完缓存的情况。因此,先更新数据库,再删除缓存的方案,是可以保证数据一致性的。同时可以为缓存引入过期时间兜底。缺点是影响缓存命中率。
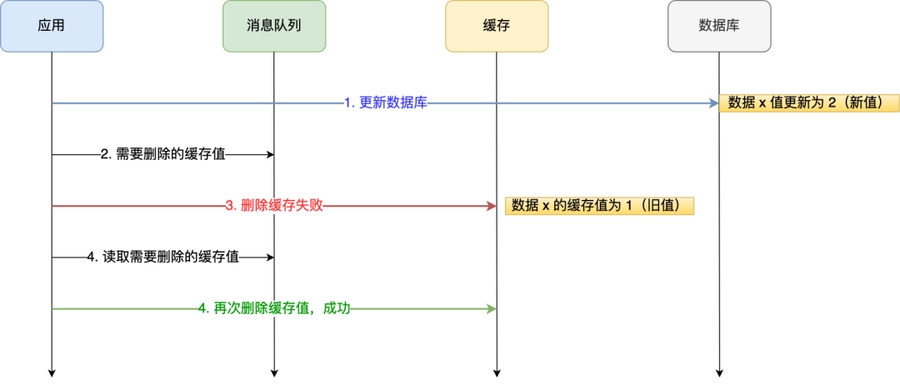
如果某个操作执行失败呢?比如说删除失败,导致触发兜底造成延迟。有两种办法,目标是异步操作缓存:
重试机制(引入消息队列)
订阅数据库
binlog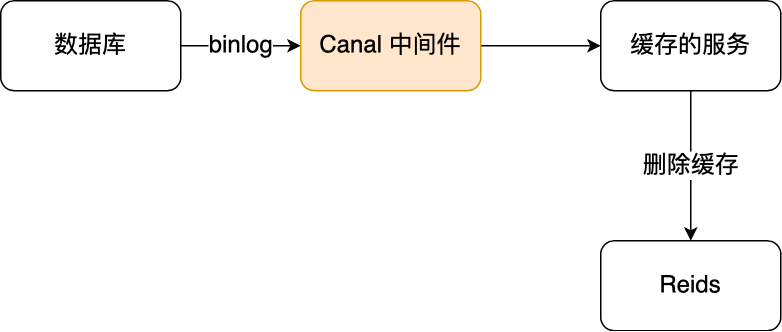
实践
电商设计手册-开源项目 [有赞保险业务的分析与架构设计-有赞技术团队-2021](https://tech.youzan.com/analysis and design of insurance system/)
优惠券系统设计: [实战!如何从零搭建10万级QPS大流量、高并发优惠券系统-字节跳动技术团 队-2022](https://mp.weixin.com/s/iZ9BX6cCCp TB-SC3knuew) vivo全球商城:优惠券系统架构设计与实践-vivo互联网技术-2021
抽奖系统设计 如何设计百万人抽奖系统-一条coding-2021. [如何设计一个百万级用户的抽奖系统?-狸猫技术窝-2019](https://juejin.cn/post/6844903847031226382
硬核课堂 Timeline Feed系统设计 - 飞书云文档 (feishu.cn) 从0到1再到N,探索亿级流量的IM架构演绎 - 飞书云文档 (feishu.cn) 实现一个短域名系统 - 飞书云文档 (feishu.cn) 如何设计一个分布式限流系统? - 飞书云文档 (feishu.cn) 高性能c++日志库 - 飞书云文档 (feishu.cn)
Appendix
延迟数

最后更新于