项目系列
项目中间件实践
线程池参数

为保持进入线程池后的任务线程也能获取到threadLocal,有一些支持继承关系的threadLocal类: 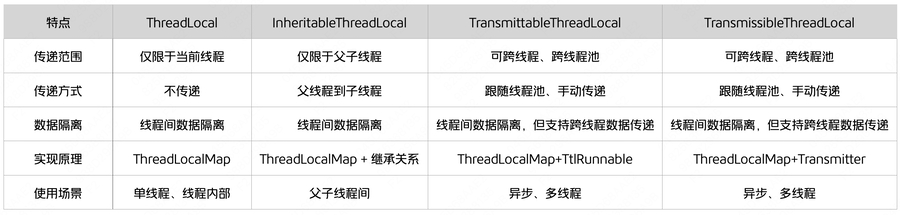
长尾延迟
一般来说,我们使用 P95 和 P99 衡量可用性。如果p99分位的延迟与p95分位的数值差距巨大,就说明该系统存在长尾延迟问题。 而由于请求的响应时间取决于最慢的下游节点的返回,其影响面通常不只是1%。
请求容错技术
backup request
如果请求的耗时超过了pct95的值,那么就触发buckup request,请求副本节点。如果buckup request提前于pct99之前返回,则优化是有效的,这一策略叫做对冲请求(对高延迟的风险对冲),这是以增加了5%请求数为代价的。
为了减少资源浪费,优先返回结果的请求节点可以告知其他节点请求已经被处理,或者组成请求数,通过绑定请求策略告知其他节点取消请求的执行。
在一次请求内的优化空间是有限的,会缺少很多有效的全局信息进行决策。
分区副本数自适应策略
互联网的马太效应会导致部分数据的访问会异常高频,成为热点,依旧会造成负载不均衡,进而产生长尾延迟。针对这一情况,需要对分区创建副本,由副本分担读取压力(写的压力通常需要一致性算法如:raft)。同时热点数据可能会动态变化,基于上面的情况可以使用一种自适应方法:
计算哪些分区具有热点:对GET的埋点记录进行流式分析
动态增加副本数量,在热点消退时释放多余的副本
延迟熔断策略
当上游发现请求下游某个节点的延迟超过了p99,那么应该将其隔离,在一段时间内不再请求该节点而是请求其他副本,完成请求。通常这里的设计艺术性在于隔离的时长应该如何确定,以及何时触发隔离的间值,通常与tcp的拥塞控制原理差不多。
降级策略
高扇出的计算任务,允许使用采样/近似/随机等计算手段简化。
常识
使用用户id作为分库分表的路由因子。这样可以保证同一个用户路由至相同的库表,既有利于数据的聚合,也方便用户数据的查询。
线上问题排查
机器资源占用率100%
通过
htop(top命令的modern版本),定位到占用资源过多的进程。perf是Linux性能分析的强大工具。使用perf top可以实时查看CPU消耗的函数或指令。可以使用
strace来追踪进程执行的系统调用和信号。可以检查/var/log/syslog、/var/log/messages等系统日志文件。
磁盘异常占用
异常连接数过多
主题问题
性能
从高度抽象的角度来看,性能问题逃不出网络 磁盘 复杂度 三个方面。解决方案也就从 并发、压缩、批量、缓存、算法 方面考虑。
统计
热Key(CMS算法)
Count-Min Sketch(CMS)是一种概率数据结构,使用有限内存近似对多项数据的频率进行计数。 它尤其适用于处理大规模数据流。应用在本地缓存Caffeine里。
以下是CMS的基本特点和工作原理:
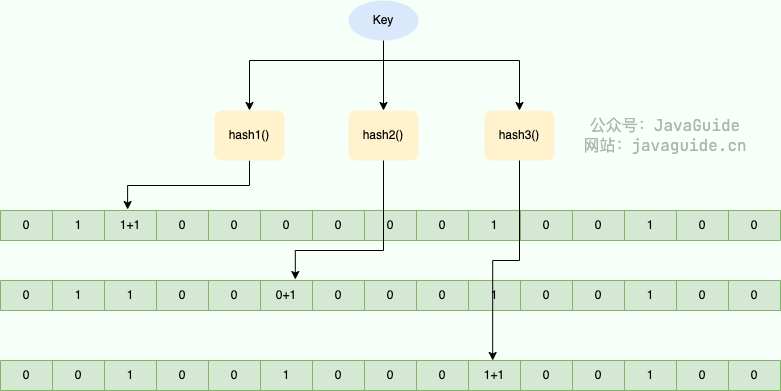
基本思想:
CMS使用多个哈希函数和一个二维数组(称为sketch表)来存储频率信息。
每个哈希函数将数据映射到sketch表的一行中的一个位置。
通过增加该位置的计数来记录数据项的到来。
插入操作:
当新数据项到达时,使用所有哈希函数进行哈希。
对于每个哈希函数,找到对应的sketch表的位置并增加其计数。
查询操作:
要估计数据项的频率,将其哈希到每一行,然后从每一行取得相应位置的计数。
返回所有行的最小计数值作为频率的估计。这样做的原因是,虽然某些哈希碰撞可能导致过高的计数,但取最小值可以为我们提供一个上限估计。
误差和置信度:
CMS提供了有关数据项频率的估计值,但这个估计值可能高于实际值。
通过调整sketch表的大小和使用的哈希函数的数量,可以控制误差和置信度。
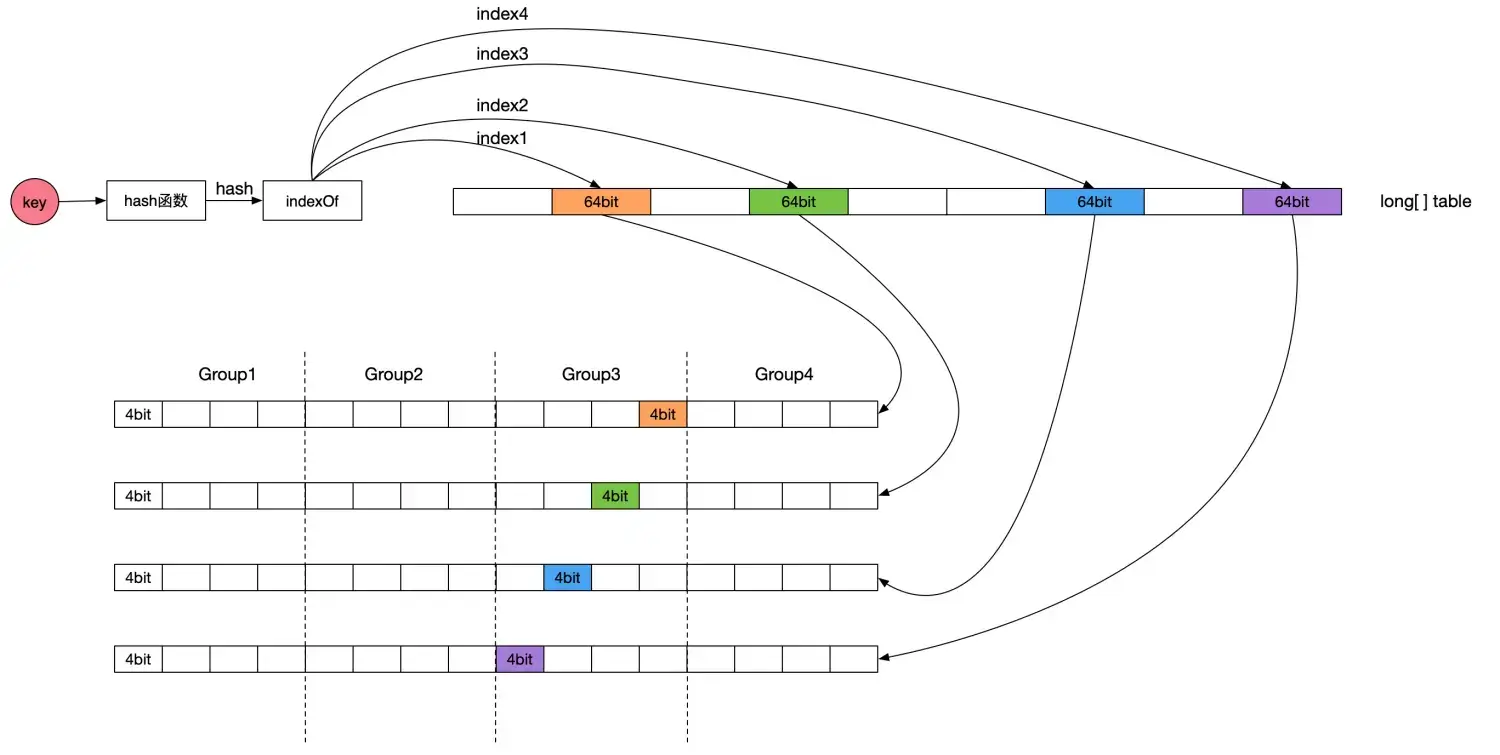
实践考虑
最后更新于