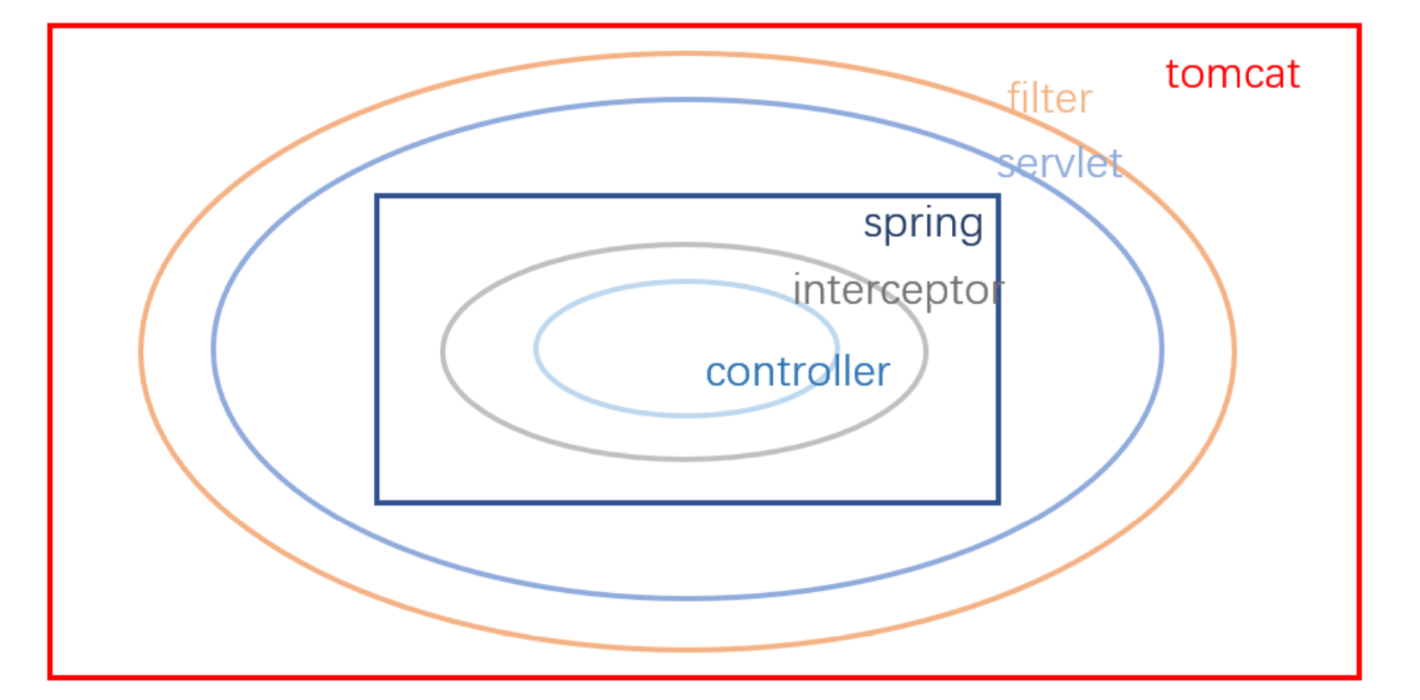
SpringBoot项目介绍
SpringBoot in 项目
常用注解和目录
Config层:放配置类
@ComponentScan:配置要交给Spring管理的类路径。如果启动类不在类路径下,需要加这个注解。
Controller层用于定义接口,是请求的入口
@RestController注解用于声明返回文本数据,一般返回JSON数据。@Controller注解用于声明返回界面。@RestController = @Controller + @ResponseBody
用@Value来读自定义配置项
@GetMapping("/hello")
== @RequestMapping(value="/hello",method=RequestMethod.GET)
@SpringBootApplication == @EnableAutoConfiguration + @ComponentScanValidation校验注解:
@NotNull(message = “该实体不能为空”)
通过引入了
devtools,实现热加载。
接口设计
后端会有很多的接口,为了让前端能够统一处理逻辑(登录校验、权限校验),需要统一后端的返回值。
级别 0
级别 0 的 API 的客户端通过向其唯一的 URL 端点发送 HTTP POST 请求来调用 该服务。每个请求被指定要执行的操作、操作的目标(如业务对象)以及参数。
级别 1
级别 1 的 API 支持资源 概念。要对资源执行修改,客户端会创建一个 POST 请求,指定要执行的操作和参数。
级别 2
级别 2 的 API 使用 HTTP 动词(谓词)执行操作:使用 GET 检索、使用 POST 创建和使用 PUT 进行更新。请求查询参数和请求体(如果有)指定操作的参数。这使服务能够利用到 Web 的基础特性,如缓存 GET 请求。
级别 3
级别 3 的 API 基于非常规命名原则设计,HATEOAS(Hypermedia as the engine of application state,超媒体即应用状态引擎)。基本思想是 GET 请求返回的资源的表述,包含用于执行该资源允许的操作的链接。例如,发送 GET 请求检索订单,返回的订单响应中包含取消订单链接,客户端可以用该链接来取消订单,由此不再需要将 URL 硬编码在客户端代码中。由于资源的表示包含可允许操作的链接,所以客户端不必猜测可以对当前状态的资源执行什么操作。
新建resp包,新建用于统一处理返回前端的实体响应类CommonResp。
使用过滤器记录接口耗时
使用拦截器记录接口耗时:配置Interceptor和web全局配置类
使用AOP记录接口耗时:配置切面类
aspect
AJAX 请求:对于 Web 应用程序,浏览器通常会发送 AJAX 请求来获取自动完成结果。 AJAX 的主要好处是发送/接收请求/响应不会刷新整个网页。
解决跨域
同源策略指的是:协议+域名+端口三者皆相同,可以视为在同一个域,否则为不同域。同源策略限制了从同一个源加载的文档或脚本与来自另一个源的资源进行交互。是一个用于隔离潜在恶意文件的重要安全机制。
跨域的解决方案
jsonp:只支持 GET,不支持 POST 请求,不安全 XSS
cors:需要后台配合进行相关的设置。使用额外的 HTTP 头来告诉浏览器让运行在一个 origin (domain) 上的 Web 应用被准许访问来自不同源服务器上的指定的资源。
postMessage:配合使用 iframe,需要兼容 IE6、7、8、9
document.domain:仅限于同一域名下的子域
websocket:需要后台配合修改协议,不兼容,需要使用 http://socket.io
proxy:使用代理去避开跨域请求,需要修改 nginx、apache 等的配置
浏览器将 CORS 请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request)。如果是复杂请求,那么在进行真正的请求之前,浏览器会先使用 OPTIONS 方法发送一个预检请求 (preflight request),携带下面两个首部字段:
Access-Control-Request-Method: 这个字段表明了请求的方法;Access-Control-Request-Headers: 这个字段表明了这个请求的 Headers;Origin: 这个字段表明了请求发出的域。 服务端收到请求后,会以Access-Control-* response headers的形式对客户端进行回复:Access-Control-Allow-Origin: 能够被允许发出这个请求的域名,也可以使用*来表明允许所有域名;Access-Control-Allow-Methods: 用逗号分隔的被允许的请求方法的列表;Access-Control-Allow-Headers: 用逗号分隔的被允许的请求头部字段的列表;Access-Control-Max-Age: 这个预检请求能被缓存的最长时间,在缓存时间内,同一个请求不会再次发出预检请求。
Nginx 是一种高性能的反向代理服务器,可以用来轻松解决跨域问题。相当于起了一个跳板机。
解决前后端交互Long类型精度丢失
JWT
传统的Session 认证需要服务器内存维护所有用户的登录信息,开销大。
Json web token是有意义的、加密的、包含业务信息的。特性:无状态。由:Header Payload Signature 三个部分组成,分别描述:元数据(数据算法)、Json字段(如:用户名、登录时间)、数据签名(哈希校验)。
Spring登录机制的实现
引入
jjwt依赖。拦截器。
如果需要踢掉不良登录态的用户,可以在用户模型中引入一个版本或时间戳字段。每当用户的凭证被更改(例如密码更改或强制注销)时,此版本号会增加。JWT中也包含这个版本号。在每次请求中,都会检查JWT中的版本号是否与存储的版本号匹配。如果不匹配,说明JWT是一个旧的或被撤销的令牌。
ref: JWT 超详细分析 | Laravel China 社区 (learnku.com)
30天趋势图的SQL语句?
SnowFlake
分布式ID生成一个很小但是很重要的基础应用。UUID保证对在同一时空中的所有机器都是唯一的。UUID的缺点是太长(32位),并且既有数字又有字母。如果想要生成纯数字的id,则Twitter的SnowFlake是一个非常优秀的id生成方案。
“在每秒产生10亿个UUIDs,大约100年后,创造一个重复的概率会达到50%”——wikipedia
实现也非常简单,SnowFlake就是由毫秒级的时间41位 + 机器ID 10位 + 毫秒内序列12位组成。当然也可以根据需要调整机器位数和毫秒内序列位数比例(可以比UUID短,一般9-17位左右),性能也很出色。

中间件:MQ
Why MQ?
以秒杀系统为例:
异步处理:秒杀系统中,有一些操作(短信通知、统计数据更新)的优先级较低,便可通过消息队列延后执行,更快地返回结果,自然实现了步骤之间的并发,提升系统总体的性能。
流量控制:使用消息队列隔离网关和后端服务,达到“削峰填谷”的作用,而不是直接过载拒绝请求返回错误。后端服务从请求消息队列中获取请求,完成后续秒杀处理过程。
通过
token桶队列,用池化思路可减小复杂度。
服务解耦:引入消息队列后,订单服务在订单变化时发送一条消息到消息队列的一个主题 Order 中,所有下游系统都订阅主题 Order,这样每个下游系统都可以获得一份实时完整的订单数据,而不是多次请求获取新的。
也要认识到,消息队列也有它自身的局限性,包括:系统响应延迟问题;增加了系统的复杂度;可能产生数据不一致的问题。
How MQ?
RabbitMQ 是一个相当轻量级的消息队列,非常容易部署和使用,自称是世界上使用最广泛的开源消息队列。
RocketMQ 有着不错的性能,响应时延很有优势,稳定性和可靠性好。
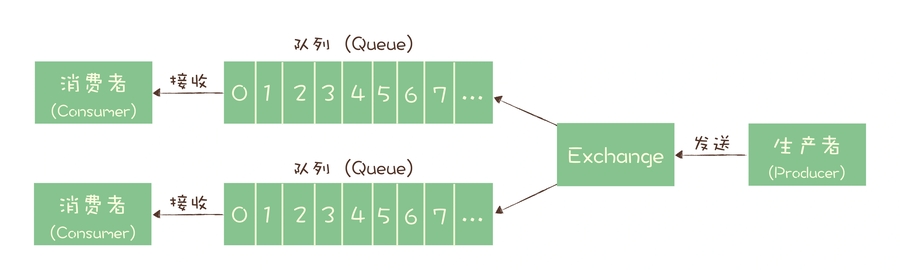
消息模型
队列模型:基础的消息模型,但是只有一个出口,不便“解耦
RabbitMQ:其设置
exchange分发层,也是其特色,提供配置支持
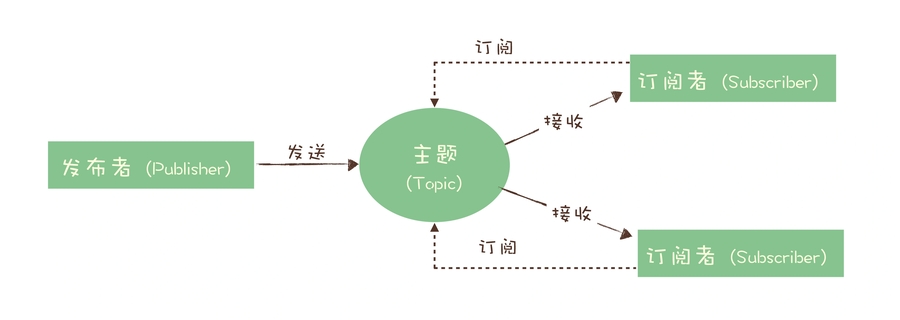
发布 - 订阅模型:一份消息数据能被消费多次。
RocketMQ:每个主题包含多个队列,通过多个队列来实现多实例并行生产和消费。 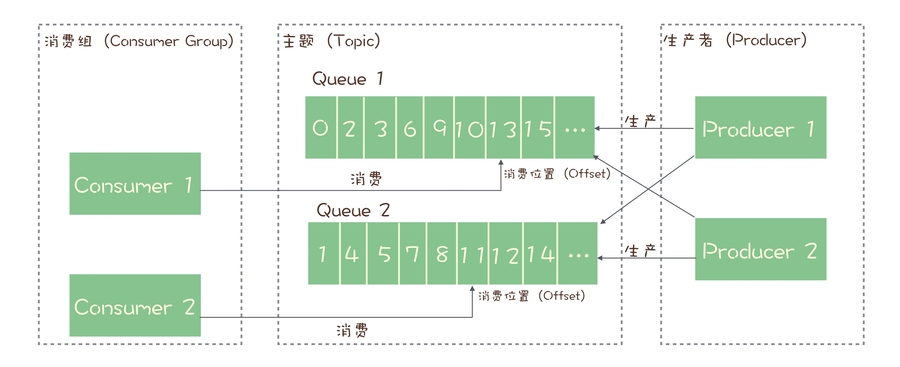
使用 RocketMQ 事务消息功能实现分布式事务的流程如下图: 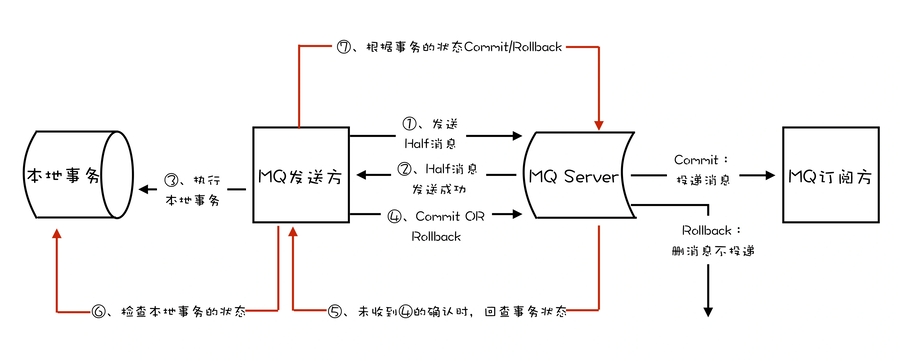
MQ的可靠性
不丢失
利用消息队列的有序性可验证是否有消息丢失。在 Producer 端,我们给每个发出的消息附加一个连续递增的序号,然后在 Consumer 端来检查这个序号的连续性。可以利用框架的拦截器机制,在 Producer 发送消息之前的拦截器中将序号注入到消息中。
在生产阶段,可设置中间件消息发送的响应
ACK,若错误并重发消息。在存储阶段,可以通过配置刷盘和复制相关的参数,让消息写入到多个副本的磁盘上,来确保消息不会因为某个 Broker(存储中间件) 宕机或者磁盘损坏而丢失。
在消费阶段,需要在处理完全部消费业务逻辑之后,再发送消费确认。
既然上面提到了“重传”,若消息重复呢?
一般解决重复消息的办法是,在消费端,让我们消费消息的操作具备幂等性。其任意多次执行所产生的影响均与一次执行的影响相同。利用数据库的唯一约束(INSERT IF NOT EXIST)、设置前置条件(版本号)、记录并检查操作等实现。
持久化
Kafka 集群内的每条消息都有多个副本,这可以确保单点故障时消息仍然可用。
AWS SQS:默认情况下,消息在被消费前可以在队列中存储多达14天。
Which MQ?
RabbitMQ 是使用 Erlang 语言编写的一个开源消息队列。轻量级,吞吐量低,定制性小。
RocketMQ 是阿里巴巴开源的一款消息中间件,使用Java语言开发
Kafka 是高性能消息队列的代表。高吞吐率。集群部署时依赖 ZooKeeper 环境,相比其他的消息队列,运维成本要高很多,ZooKeeper 的引入,使得 Kafka 可以非常方便地进行水平扩展,支持海量数据的传输。
选型的原则: 选型时要特别注意中间件的性能和扩展性。 开源优先。 功能级别不具备一票否决权。
产品比较
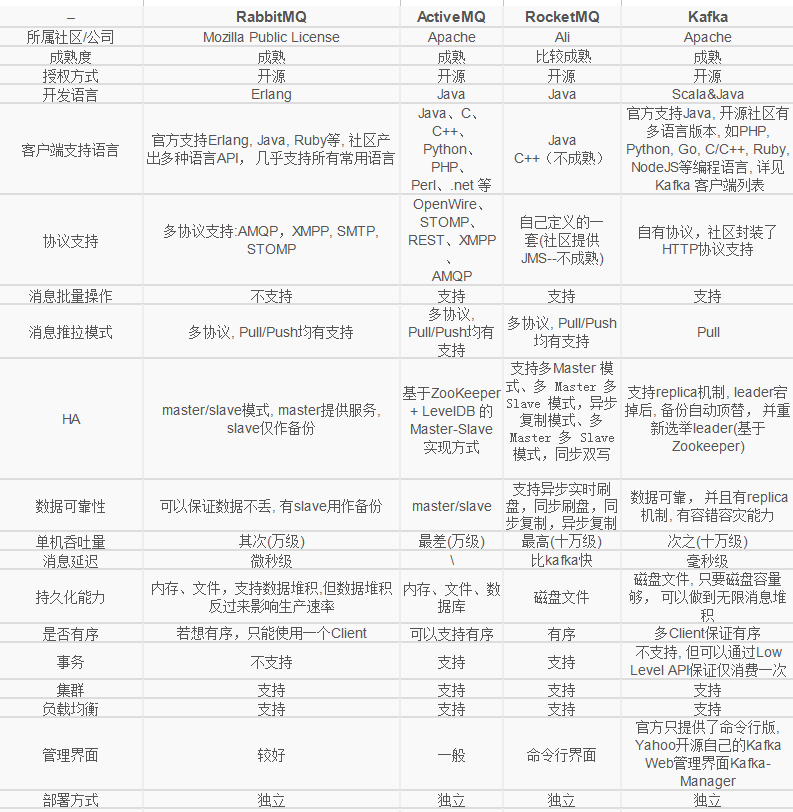
Kafka 可以在各类数据埋点中使用,比如电商营销的转化率日志收集和计算,另外,Kafka 的高性能使得特别它适合应用在各类监控、大数据分析等场景。
RocketMQ 对一致性的良好保证,可以应用在电商各级业务调用的拆分中,比如在订单完成后通知用户,物流信息更新以后对订单状态的更新等。
RabbitMQ 则可以在数据迁移、系统内部的业务调用中应用,比如一些后台数据的同步、各种客服和 CRM 系统。
技术比较
持久化
是 (磁盘)
是 (可选)
是 (KahaDB)
是 (S3)
是 (磁盘)
消息确认
生产者确认
生产者&消费者确认
消费者确认
消费者确认
生产者&消费者确认
副本/备份
副本
镜像队列
Master-Slave
不适用
副本
重试策略
是
是
是
是
是
死信队列
不适用
是
是
是
是
顺序保证
分区级别
不适用
不适用
FIFO队列
是
高可用配置
是 (集群)
集群/联邦
Master-Slave
是 (多区域)
集群
优点
高吞吐,可扩展
灵活路由
多协议支持
完全托管
高性能,低延迟
缺点
运维复杂
资源占用
性能不如Kafka
RabbitMQ 和 Kafka都更灵活
相对较新
MyBatis
MyBatis 是一款优秀的持久层框架,支持自定义 SQL、存储过程以及高级映射,免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis Generator是官方的代码生成器,可以为所有版本的MyBatis生成持久层代码。首先它会扫描一张数据库表(或者更多)然后生成一套访问表的框架。
使用来说:
配置文件,通常是
mybatis-config.xml,包含数据源、mapper文件路径等创建一个 Mapper 接口,用于定义数据库操作方法。并配置 SQL 语句和映射规则
mapperxml文件。比如
MyBatis 配置初始化: 在应用程序中初始化 MyBatis 配置和会话工厂。
使用例子:
Springboot 集成
添加依赖
在
MyBatis接口中,添加@Mapper注解。在
application.yml等中引用数据源配置xml文件,或者直接配置。
#{}和${}的区别是什么?
${}是 properties 文件中的变量占位符,它可以用于标签属性值和 sql 内部,属于静态文本替换,比如${driver}会被静态替换为com.mysql.jdbc.Driver。#{}是 sql 的参数占位符,MyBatis 会将 sql 中的#{}替换为? 号,在 sql 执行前会使用 PreparedStatement 的参数设置方法,按序给 sql 的? 号占位符设置参数值,比如 ps.setInt(0, parameterValue),#{item.name}的取值方式为使用反射从参数对象中获取 item 对象的 name 属性值,相当于param.getItem().getName()
限流
令牌桶
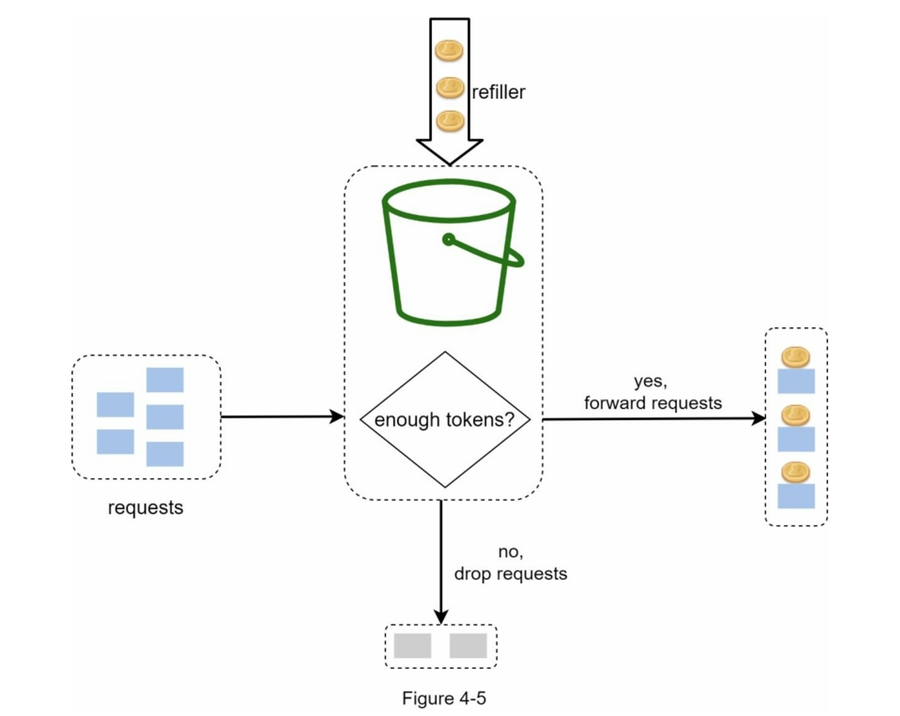
算法容易实现、节省内存
允许短时间内的流量突发
漏桶
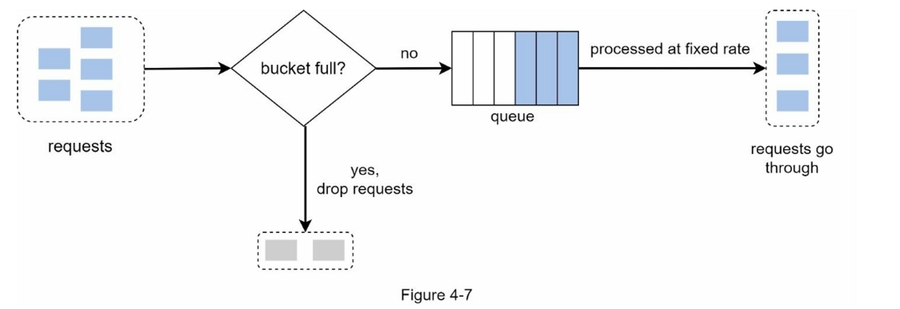
内存效率高、稳定流出速率
突发的流量使队列中充满了旧的请求,如果这些请求没有得到及时处理,最近的请求将受到速率限制。
滑动窗口
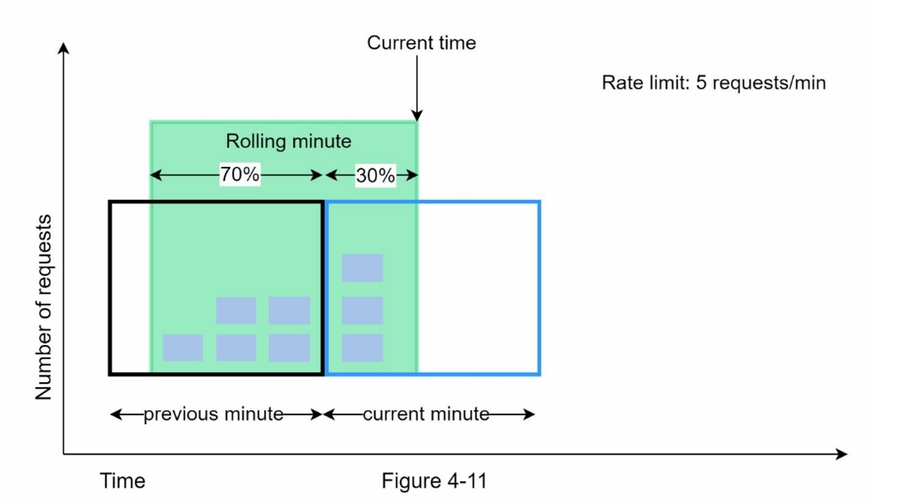
平滑了流量的峰值、内存高效
近似实现
如果一个请求被限制了速率,返回 429 too many requests 错误和 X-Ratelimit-Retry-After(秒) 标头。
websocket
帧的基本结构
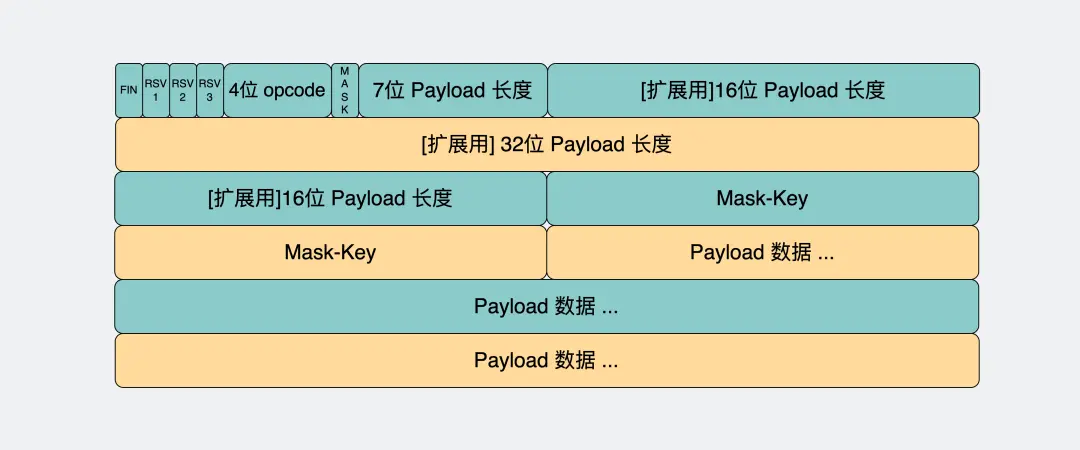
FIN (1 bit):
如果为 1,表示这是当前消息的最后一个帧(WebSocket 消息可能由一个或多个帧组成)。
如果为 0,表示消息尚未结束,后续的帧还在传输。
RSV1, RSV2, RSV3 (各 1 bit):
这三个字段目前没有明确的用途,为将来的协议扩展预留,当前版本的协议中这些位应该设为 0。
Opcode (4 bits):
定义帧的类型。例如,
0x1表示这是一个文本帧,0x2表示这是一个二进制帧。还有一些特殊的操作码,如0x8表示连接关闭,0x9表示 Ping,0xA表示 Pong。
MASK (1 bit):
用于表示负载数据是否被掩码处理。从客户端发往服务器的帧必须被掩码。
Payload length (7 bits or 7+16 bits or 7+64 bits):
用于表示负载数据的长度。如果长度为 125 以下,则使用 7 位表示;如果长度为 126,则接下来的 16 位表示真正的长度;如果长度为 127,则接下来的 64 位表示真正的长度。
Masking-key (0 or 4 bytes):
只有当 MASK 位被设为 1 时存在。它是一个 32 位的值,用于掩码或解掩码负载数据。
Payload data (variable length):
实际的消息内容。如果 MASK 位被设为 1,那么这个数据会与 Masking-key 做异或操作来进行掩码或解掩码。
相比于 HTTP 的复杂报文结构,WebSocket 的帧结构更简洁,更适用于低延迟和高频率的实时通信。特别是掩码机制和分片消息的支持,使得 WebSocket 在网络安全和大消息传输上都具有一定的灵活性。
抄袭过的代码:
SpringBoot如何优雅的将静态资源配置注入到工具类中:https://my.oschina.net/vright/blog/826184
最后更新于