Go服务框架项目
Web框架
雏形
type Handler interface {
ServeHTTP(w ResponseWriter, r *Request)
}Handler是一个接口,需要实现方法 ServeHTTP ,也就是说,只要传入任何实现了 ServerHTTP 接口的实例,所有的HTTP请求,就都交给该实例处理了。我们可以定义了一个空的结构体Engine,实现了方法ServeHTTP,将所有的HTTP请求转向了我们自己的处理逻辑。
type H map[string]interface{}
type Engine struct {
router map[string]HandlerFunc
}
func (engine *Engine) addRoute(method string, pattern string, handler HandlerFunc) {
key := method + "-" + pattern
engine.router[key] = handler
}
// http.HandleFunc 实现了路由和Handler的映射Context
对Web服务来说,无非是根据请求*http.Request,构造响应http.ResponseWriter。但是这两个对象提供的接口粒度太细,比如我们要构造一个完整的响应,需要考虑消息头(Header)和消息体(Body),而 Header 包含了状态码(StatusCode),消息类型(ContentType)等几乎每次请求都需要设置的信息。为避免冗余,针对常用场景,能够高效地构造出 HTTP 响应是一个好的框架必须考虑的点。因此,设计 Context 结构,集成http.ResponseWriter, *http.Request等。扩展性和复杂性留在了内部,而对外简化了接口。Context 随着每一个请求的出现而产生,请求的结束而销毁,和当前请求强相关的信息都应由 Context 承载。
比如说,我们雏形中的路由,就可以包装了原来的两个传参等为*context了。
Trie和动态路由
为高效地匹配路由引入Trie树,为支持动态路由,额外添加isWild字段。我们实现的动态路由具备以下两个功能。
参数匹配
:。例如/p/:lang/doc,可以匹配/p/c/doc和/p/go/doc。要对 Context 对象增加一个属性和方法,将解析后的参数存储到Params中,通过c.Param("lang")访问对应的值。通配
*。例如/static/*filepath,可以匹配/static/fav.ico,也可以匹配/static/js/jQuery.js,这种模式常用于静态服务器,能够递归地匹配子路径。
例: /p/:lang/doc只有在第三层节点,即doc节点,pattern才会设置为/p/:lang/doc。p和:lang节点的pattern属性皆为空。 因此,当匹配结束时,我们可以使用n.pattern == ""来判断路由规则是否匹配成功。
我们定义两个map:
roots :存储每种请求方式的Trie 树根节点。
handlers :存储每种请求方式的 HandlerFunc 。
系统设计搜索自动补全的topK问题中,可以定制化Trie树实现。为了避免遍历整个 trie,我们在每个节点存储前 k 个最常用的查询。比如:
另外,对于Trie树的更新需要根据业务需求定制化策略。如果树很大,直接更新单个 trie 节点是不实惠的。对于实时性要求不高的场景,可以每周根据分析性日志重建 trie。 可以在 Trie 缓存前面添加一个过滤层以过滤掉不符合规则的搜索建议。
中间件和分组路由
分组,是指路由的分组。实际中,往往某一组路由需要相似的处理。如:以/api开头的路由是 RESTful 接口,可以对接第三方平台,需要三方平台鉴权。
中间件(middleware),简单说,就是非业务的技术类组件。框架需要有一个插口,允许用户自己定义功能,嵌入到框架中。即,在context.go中新加两个字段:
举例中间件:
则达到了从前往后调用,再从后往前执行每个中间件在Next方法之后定义的部分。作用在/post分组上的中间件,也都会作用在子分组,子分组还可以应用自己特有的中间件。例如/admin的分组,可以应用鉴权中间件;/分组应用日志中间件(默认的最顶层的分组,也就意味着给所有的路由,即整个框架增加了记录日志的能力)。
我们还可以进一步地抽象,将Engine作为最顶层的分组,也就是说Engine拥有RouterGroup所有的能力。那我们就可以将和路由有关的函数,都交给RouterGroup实现了。
Gee-Cache
缓存值以type byteview进行封装,使用LRU(with mutex)进行并发控制。
对于多条缓存通路,如何回调?
调用该接口的方法Get实际上就是在调用匿名回调函数。
group
Group 是 GeeCache 最核心的数据结构,负责与用户的交互,并且控制缓存值存储和获取的流程。
分布式节点
我们使用一致性哈希(为减少数据倾斜,引入虚拟节点,维护映射)选择节点。抽象出两个接口:
我们需要创建具体的 HTTP 客户端类 httpGetter,实现 PeerGetter 接口。PickerPeer() 包装了一致性哈希算法的 Get() 方法,根据具体的 key,选择节点,返回节点对应的 HTTP 客户端。其中可以引入protobuf:
ServeHTTP()中使用proto.Marshal()编码 HTTP 响应。Get()中使用proto.Unmarshal()解码 HTTP 响应。
处理缓存击穿
实现方法Do(key string, fn func() (interface{}, error)) (interface{}, error),针对相同的 key,无论 Do 被调用多少次,函数 fn 都只会被调用一次,等待 fn 调用结束返回值或错误。
附录:缓存选型
本地缓存与应用属于同一个进程,主要的优势是没有网络访问开销。如Caffeine。其对单体应用非常友好,但对分布式应用就会显得有点浪费资源,因为数据发生变化时,需要通知多台机器同时刷新缓存;或是受到负载均衡组件的影响,不同节点缓存同一份数据,这就造成了资源浪费。因此,本地缓存更适合存储一些变化频率极低,数据量较小(存在单点故障与资源瓶颈)的场景,诸如基础数据、配置了类型的数据缓存等。
由于分布式缓存与应用进程分属不同的进程,存在网络访问开销,所以几乎各个缓存中间件都是基于内存存储的系统,它们的存储容量受限于机器内存容量。比如,
使用一致性哈希算法进行负载均衡,主要是为了提高节点扩容、缩容时的缓存命中率。
Redis 采用master-slave 同步模式(会引入哨兵集群),这可以提升数据的存储可靠性。如果是像 Memcache 这种不能持久化的中间件,进程一旦退出,存储在内存中的数据将会丢失,就要重新从数据库加载数据,这会让大量流量在短时间内穿透到数据库(击穿),造成数据库层面不稳定。
Memcache 基于多线程运行模型,可以充分利用多核 CPU 的并发优势,提升资源的利用率。
GeeORM
服务结构
执行完成后,清空 (s *Session).sql 和 (s *Session).sqlVars 两个变量(用户调用 Raw() 方法即可改变这两个变量的值)。这样 Session 可以复用,开启一次会话,可以执行多次 SQL。
Engine 是 GeeORM 与用户交互的入口,封装连接、检查数据库是否能够正常响应等。
ORM 框架往往需要兼容多种数据库,因此我们需要将差异的这一部分提取出来,每一种数据库分别实现,实现最大程度的复用和解耦。这部分代码称之为 dialect。接口包含 2 个方法:
DataTypeOf用于将 Go 语言的类型转换为该数据库的数据类型。TableExistSQL返回某个表是否存在的 SQL 语句,参数是表名(table)。
对象表结构映射
后面涉及一些反射判断等方法,在此省略。
Hook钩子
Hook,翻译为钩子,其主要思想是提前在可能增加功能的地方埋好(预设)一个钩子,当我们需要重新修改或者增加这个地方的逻辑的时候,把扩展的类或者方法挂载到这个点即可。我的理解是,基于反射判断实现的触发器。接下来,将实现的 CallMethod() 方法在 Find、Insert、Update、Delete 方法前后调用即可(如:s.CallMethod(BeforeUpdate, nil))。
事务
如果要支持事务,需要更改为 sql.Tx 执行。在 Session 结构体中新增成员变量 tx *sql.Tx,当 tx 不为空时,则使用 tx 执行 SQL 语句,否则使用 db 执行 SQL 语句。这样既兼容了原有的执行方式,又提供了对事务的支持。
用户只需要将所有的操作放到一个回调函数中,作为入参传递给 engine.Transaction(),发生任何错误,自动回滚,如果没有错误发生,则提交。
GeeRPC
RPC基础知识
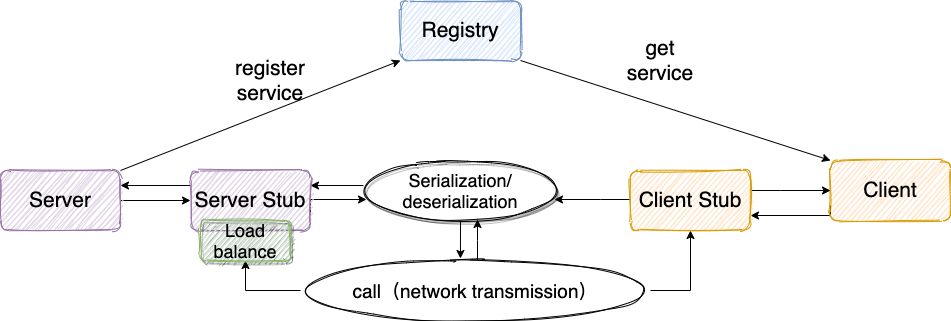
Client Stub(桩):代理类。负责序列化调用方法、类、方法参数等信息和消息发送,或者反序列化返回体。
Server Stub(skeleton) :接收到客户端执行方法的请求后,去指定对应的方法然后返回结果给客户端的类。负责反序列化、调用并组装返回体。
常见RPC框架对比
设计语言
Java,跨语言建议用后两种
Interface Definition Language (IDL)
Protocol Buffers (ProtoBuf)
通信协议
RMI, HTTP(Triple)
Binary, Compact, JSON, ...
HTTP/2 with ProtoBuf
服务发现
是,应用级
通常与其他工具如Zookeeper结合
需要与其他工具如etcd、Consul结合
负载均衡
是
客户端
客户端和服务端
持久连接
是
取决于传输方式
是
流量控制
是
通常没有
是
推荐使用场景
提供了从服务定义、服务发现、服务通信到流量管控等几乎所有的服务治理能力 Dubbo Mesh对云原生支持很友好 适合微服务架构
跨语言服务调用
几乎没有服务治理能力(可以使用北极星)流处理、云原生应用
消息编解码
即codec模块。本次支持gob包编码。(demo中,协商的唯一内容是消息的编解码方式)
首先定义codec接口,抽象出 Codec 的构造函数,客户端和服务端可以通过 Codec 的 Type 得到构造函数,从而创建 Codec 实例。这部分代码和工厂模式类似,与工厂模式不同的是,返回的是构造函数,而非实例。
实现GobCodec 结构体,这个结构体由四部分构成,conn 是由构建函数传入,通常是通过 TCP 或者 Unix 建立 socket 时得到的链接实例,dec 和 enc 对应 gob 的 Decoder 和 Encoder,buf 是为了防止阻塞而创建的带缓冲的 Writer,一般这么做能提升性能。
为了实现简单,客户端固定采用 JSON 编码 Option,后续的 header 和 body 的编码方式由 Option 中的 CodeType 指定,服务端首先使用 JSON 解码 Option,然后通过 Option 的 CodeType 解码剩余的内容。即报文将以这样的形式发送:
在一次连接中,Option 固定在报文的最开始,Header 和 Body 可以多个,即报文可能是这样的: Option | Header1 | Body1 | Header2 | Body2 | ...
服务端如下提供服务:
函数客户端与服务注册
对 net/rpc 而言,一个函数需要能够被远程调用,需要满足如下五个条件:
the method’s type is exported.
the method is exported.
the method has two arguments, both exported (or builtin) types.
the method’s second argument is a pointer.
the method has return type error. – 返回值有且只有 1 个,为 error 类型。
为了支持异步调用,Call 结构体除
seq, method, args, reply, err外,添加了一个字段Done chan *Call,当调用结束时,会调用call.done()通知调用方。
创建 Client 实例时,首先需要完成一开始的协议交换,即发送 Option 信息给服务端。协商好消息的编解码方式之后,再创建一个子协程调用 receive() 接收响应(s。还需要实现 func Dial(network, address string, opts ...*Option) (client *Client, err error) 函数,便于用户传入服务端地址(server中的ServeConn函数在循环等待请求以执行对应函数,main通过server addr调用Dial建立client),创建 Client 实例。其中,通过 ...*Option 将 Option 实现为可选参数。实现中
Go和Call是客户端暴露给用户的两个 RPC 服务调用接口,Go是一个异步接口,返回 call 实例。Call是对Go的封装,阻塞 call.Done,等待响应返回,是一个同步接口。
如何实现ServiceMethod到函数体的映射?通过反射,我们能够非常容易地获取某个结构体的所有方法,并且能够通过方法,获取到该方法所有的参数类型与返回值。
超时处理机制
纵观整个远程调用的过程, 需要客户端处理超时的地方有:
与服务端建立连接,导致的超时
发送请求到服务端,写报文导致的超时
等待服务端处理时,等待处理导致的超时(比如服务端已挂死,迟迟不响应)
从服务端接收响应时,读报文导致的超时
需要服务端处理超时的地方有:
读取客户端请求报文时,读报文导致的超时
发送响应报文时,写报文导致的超时
调用映射服务的方法时,处理报文导致的超时
为实现方便,由Option结构体添加超时设定, 在 3 个地方添加了超时处理机制。分别是:
客户端创建连接时 (
Dial->DialTimeout,并使用子协程执行 NewClient,执行完成后则通过信道 ch 发送结果,如果time.After()信道先接收到消息,则说明 NewClient 执行超时,返回错误。)Client.Call()整个过程导致的超时(包含发送报文,等待处理,接收报文所有阶段,使用 context 实现,作为参数传,控制权交给用户,如ctx, _ := context.WithTimeout(context.Background(), time.Second))服务端处理报文,即
Server.handleRequest超时。
负载均衡
当然是先有多个服务实例,再谈负载均衡。首先实现一个手动的服务发现:
根据服务发现实例 Discovery、负载均衡模式 SelectMode 以及协议选项 Option,构造客户端XClient,为了尽量地复用已经创建好的 Socket 连接,使用 clients map[string]*Client 保存创建成功的 Client 实例,并提供 Close 方法在结束后,关闭已经建立的连接。此能力封装在方法 dial 中,dial 的处理逻辑如下:
检查
xc.clients是否有缓存的 Client,如果有,检查是否是可用状态,如果是则返回缓存的 Client,如果不可用,则从缓存中删除。如果步骤 1) 没有返回缓存的 Client,则说明需要创建新的 Client,缓存并返回。
除了Call 外,还实现 Broadcast 将请求广播到所有的服务实例,如果任意一个实例发生错误,则返回其中一个错误,取消其他call;如果调用成功,则返回其中一个的结果。有以下几点需要注意:
为了提升性能,请求是并发的。使用
replyDone变量保证只返回一次。并发情况下需要使用互斥锁保证 error 和 reply 能被正确赋值。
借助 context.WithCancel 确保有错误发生时,快速失败。
基于注册中心的服务发现
相比于手动维护,可以保证服务端是否处于可用状态,工业界还可以配置的动态同步、通知机制等。首先定义 GeeRegistry 结构体,默认超时时间设置为 5 min,并实现
putServer:添加服务实例,如果服务已经存在,则更新 start。
aliveServers:返回可用的服务列表,如果存在超时的服务,则删除。
发现:
Thanks: https://geektutu.com/post/gee.html
最后更新于