JVM执行引擎
前端编译及优化
Javac编译过程
准备过程:初始化插入式注解处理器。
处理过程:

参考《编译原理》,此处略。
语法糖
类型擦除型泛型
与C#的“具现化性范型“不同,Java中的泛型只在程序源码中存在,在字节码时已替换为具体类型,无法当成真实类型使用。因此,对范型进行实例判断、创建泛型对象是不合法的行为。
裸类型 , 视为所有该泛型化实例的共同父类型。
后端编译与优化
即时编译器JIT
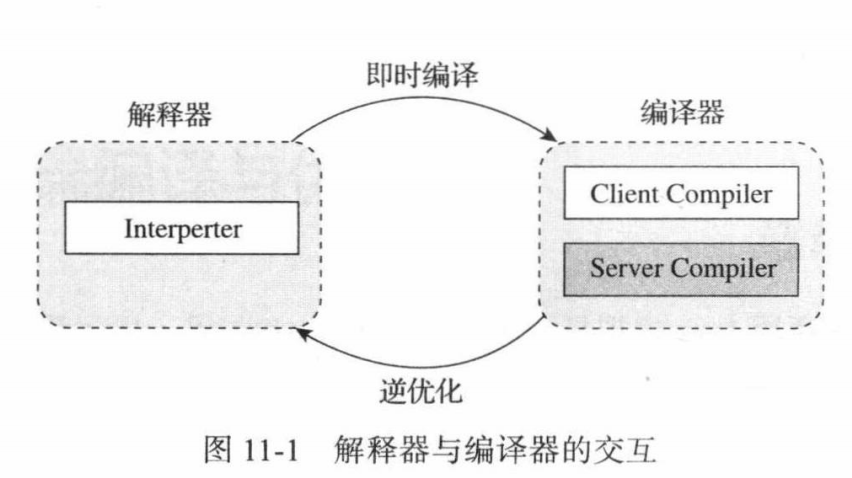
编译模式:代码编译为本地代码
解释模式:便于程序迅速启动
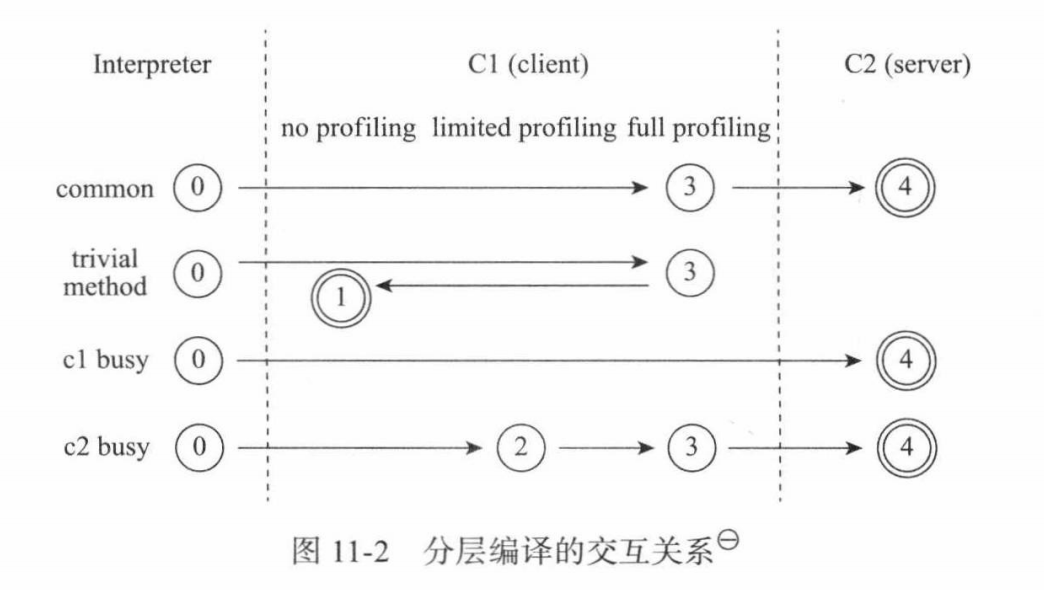
虚拟机可指定参数设置运行模式,默认为分层模式:
第0层:程序纯解释执行,解释器不开启性能监控功能(
Profiling)第1层:使用客户端编译器,进行简单可靠的稳定优化,不开启性能监控功能
第2层:使用客户端编译器,开启方法及回边次数统计等有限性能监控功能
第3层:使用客户端编译器,开启全部性能监控功能,出第2层的内容,还会
收集分支跳转、虚方法调用版本等统计信息
第4层:使用服务端编译器,会启动更多编译耗时更长的优化,且会根据监控信息进行一些不可靠的激进优化。
即时编译器编译的目标是“热点代码”方法体,即被多次调用的方法或循环体。(循环体的编译入口不同)。目前采用基于计数器的热点检测方案(还有一个主流方案是基于采样)
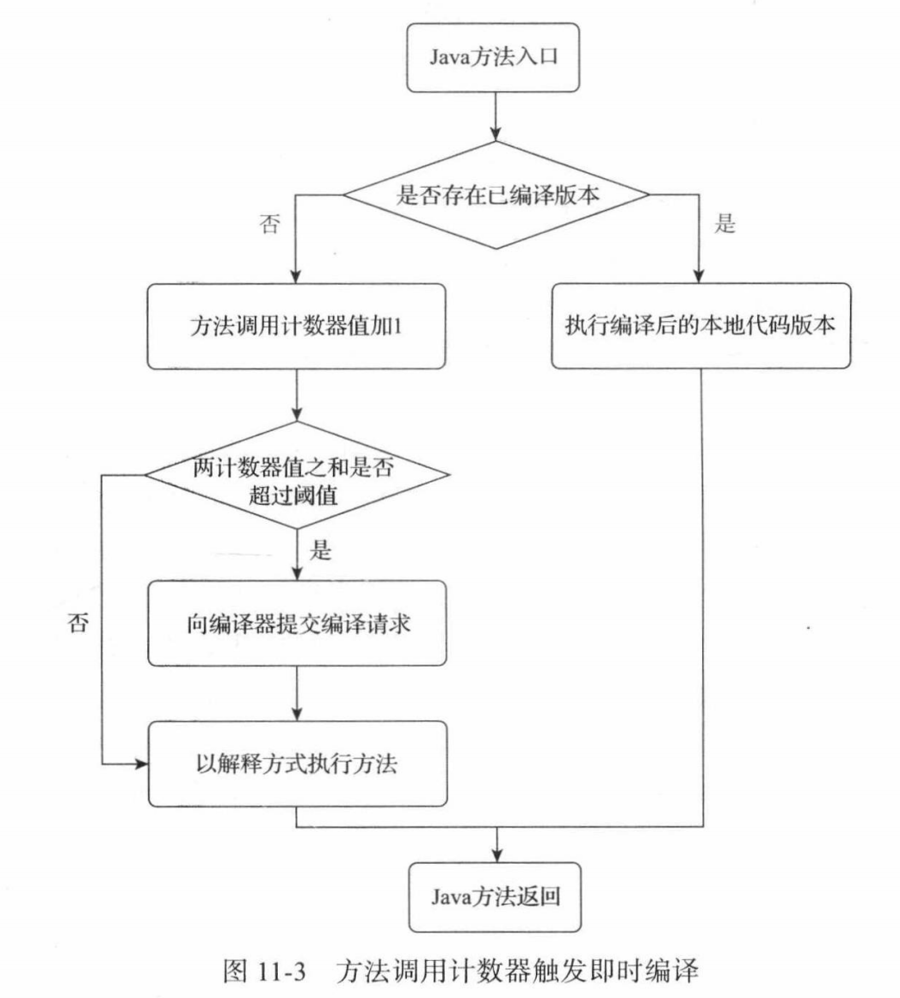
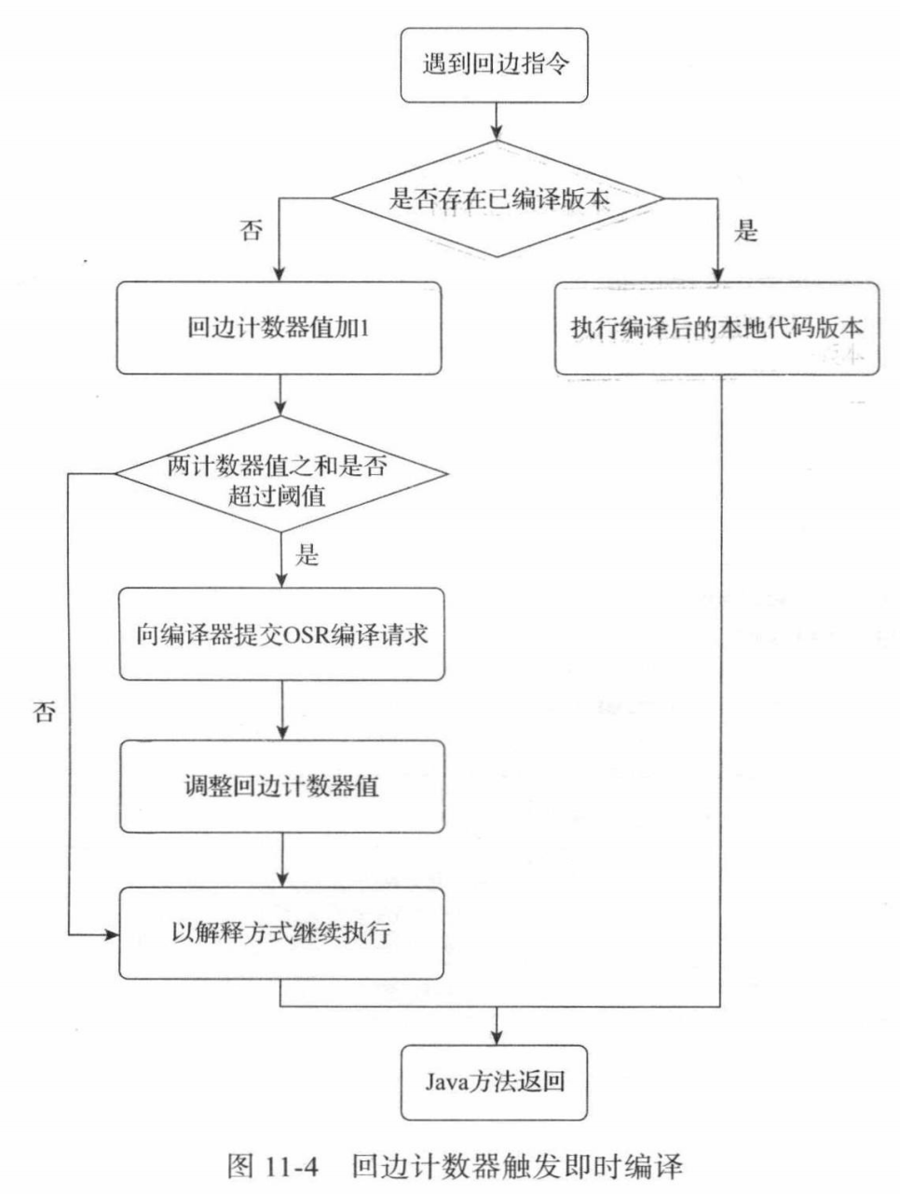
回边 的意思是在循环边界往回跳转。
方法调用计数器有半衰期,热度衰减动作由垃圾收集时顺便执行。
回边计数器没有衰减机制,统计值为绝对数字。
 (LIR:中间代码表示,SSA:静态单分派)
(LIR:中间代码表示,SSA:静态单分派)
虚拟机在代码编译未完成时会按照解释方式继续执行,编译动作在后台的编译线程执行。
提前编译器
可以说是抛弃一些比较耗时的优化策略,选择替代方案,应用过程内分析模拟 和 缓存加速 作为实现方向。
即时编译器的优势在于:
性能分析制导优化
激进预测性优化
链接时优化
编译器优化技术
方法内联
方法内联被称为优化之母,除了消除方法调用的成本之外,更重要的意义是为其他优化手段建立良好的基础。
对于虚方法,Java虚拟机引入类型继承关系分析 技术CHA,确定虚方法的接口、类关系信息,如果只有一个方法版本则进行守护内联 (假设只有这个版本)并预留继承关系发生变化时的回滚解释状态;若有多个版本,使用内联缓存方式。
逃逸分析
是目前Java虚拟机中比较前沿的优化技术,其基本原理是:分析对象动态作用域,当一个对象在方法里面被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,这种称为方法逃逸;甚至可能被外部线程访问到,譬如赋值给可以在其他线程中访问的实例变量,这种称为线程逃逸。
如果逃逸程度在线程逃逸之下(即不会被别的线程引用):
栈上分配优化。使该对象在栈上分配内存,对应内存空间随栈帧出栈而销毁。
标量替换优化。标量指不可再分解的数据,如基本数据类型,否则称作聚合量。对于方法逃逸之下 的对象,可将对象的成员变量拆散为基本数据类型们,而不去创建对象体,在栈上分配与读写。
同步消除优化。关闭线程间同步措施。
公共子表达式消除
如果表达式 E 已经被计算过了,并且到现在 E 中所有变量的值都没有发生变化,那么 E 的此次出现就称为公共子表达式,是冗余的。
复写传播、无用代码消除
清除额外的变量、不会被执行的代码、无意义代码等。
数组检查边界消除
根据性能监控信息,相对于每次对数组索引的判断,使用隐式异常优化可减少开销,即:
虚拟机注册异常处理器Segment Fault,使用try catch机制代替if else机制。当然,由于越界需要进入中断异常处理,速度比判空慢。
Java编译期优化分析
String系列
新时代的JVM
指针压缩技术
在32位到64位的转变中,程序最大的获益是内存容量。在一个32位系统中,内存地址的宽度就是32位,这就意味着,程序最大能获取的内存空间是2^32(4G)字节。这个容量明显不够用了。在一个64位的机器中,理论上程序能获得的内存容量是2^64字节,这是一个十分庞大的数字。不过,这个转变也是有代价的:
运行在64位中的程序会花费更多的内存。通常64位JVM消耗的内存会比32位的大
1.5倍,这是因为对象指针在64位架构下,长度会翻倍(更宽的寻址)。对于那些将要从32位平台移植到64位的应用来说,平白无故多了1/2的内存占用,这是开发者不愿意看到的。增加了GC开销。64位对象引用需要占用更多的对空间,留给其他数据的空间将会减少,从而加快了GC的发生。
降低了CPU缓存的命中率。64位对象引用(指针)增加了,CPU能缓存的指针将会减少,从而降低了CPU缓存的效率。
可以使用
lucene提供的专门用于计算堆内存占用大小的工具类:RamUsageEstimator,以便捷地计算对象占用的内存大小。
为了解决上述的问题,HotSpot引入了两个压缩优化的技术,Compressed Ordinary Object Pointers和Compressed Class Pointers。
Compressed Ordinary Object Pointers
Ordinary Object Pointers,oops 即普通对象指针。启用CompressOops后,以下对象的指针会被压缩:
每个Class的属性指针(静态成员变量)
每个对象的属性指针
普通对象数组的每个元素指针
启动压缩后,JVM保存32位的指针,但是在64位机器中,最终还是需要一个64位的地址来访问数据。这里JVM需要做一个对指针数据编码、解码的工作。在机器码中植入压缩与解压指令来实现以下过程:
首先,每个对象的大小一定是8字节的倍数,因为JVM会在对象的末尾加上数据进行对齐填充(Padding)。
假设对象x中有3个引用,a在地址0,b在地址8,c在地址16。那么在x中记录引用信息的时候,可以不记录0, 8, 16…这些数值,而是可以使用0, 1, 2…(即地址右移3位,相当于除8),这一步称为encode。在访问x.c的时候,拿到的地址信息是2,这里做一次decode(即地址左移3位,相当于乘8)得到地址16,然后就可以访问到c了。这样,虽然我们使用32位来存储指针,但是我们多出了8倍的可寻址空间。所以压缩指针的方式可以访问的内存是4G * 8 = 32G。
Compressed Class Pointers
在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
对象头包括两部分信息,第一部分用于存储对象自身的运行时数据,如哈希码、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等,这部分数据的长度在32位和64位的虚拟机中分别为32bit和64bit,官方称它为Mark Word。另外一部分是一个指向Metaspace中Klass结构(这个结构可以理解为一个Java类在虚拟机内部的表示)的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。在32位JVM中,这个指针是32位的。在64位JVM中,这个指针本来是64位的,但开启Compressed Class Pointers之后,这个指针是32位的,为了找到真正的64位地址,需要加上一个base值:
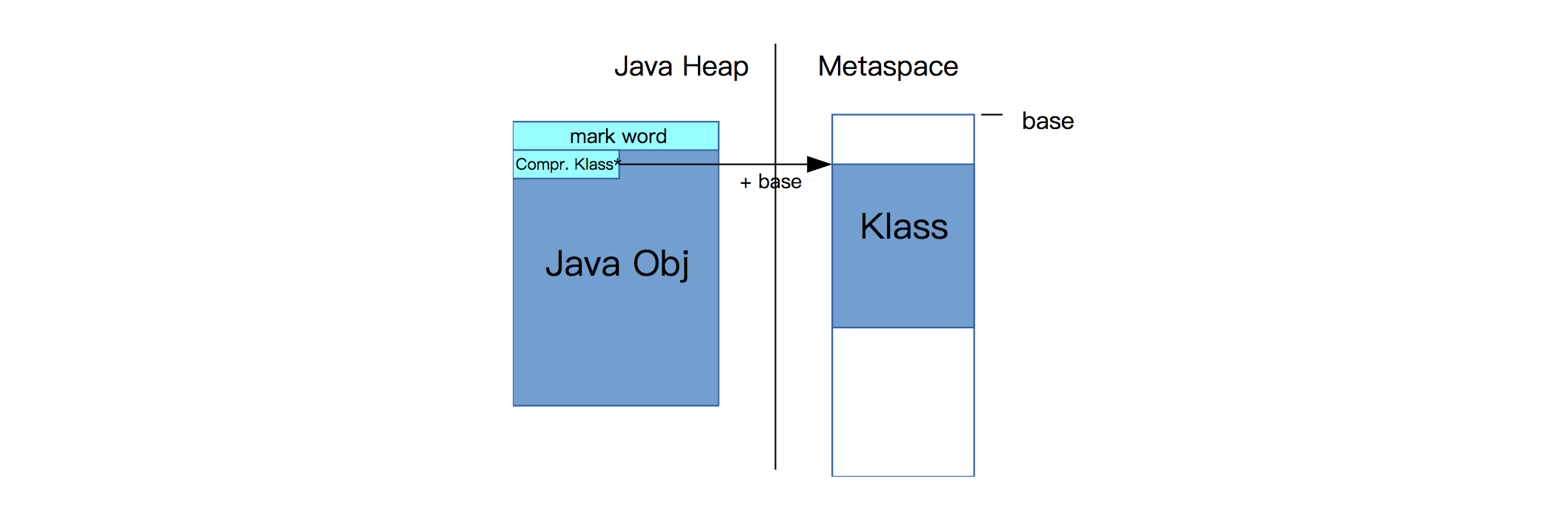
由于32位地址只能访问到4G的空间,所以最大只允许4G的Klass地址。这项限制也意味着,JVM需要向Metaspace分配一个连续的地址空间。当从系统申请内存时,通过调用系统接口malloc(3)或mmap(3),操作系统可能返回任意一个地址值,所以在64位系统中,它并不能保证在4G的范围内。所以,我们只能用一个mmap()来申请一个区域单独用来存放Klass对象。 我们需要提前知道这个区域的大小,而且不能超过4G。显然,这种方式是不能扩展的,因为这个地址后面的内存可能是被占用的。因此Metaspace分为两个区域:
class part:存放Klass对象,需要一个连续的不超过4G的内存。non-class part:包含其他的所有metadata。其他的metadata都是通过64位的地址进行访问的,所以它们可以被放到任意的地址上。除了Klass,metadata还包括:Method metadata方法元数据。Java类文件中method_info结构在虚拟机内部的运行时表示,包括bytecode(字节码)、exception table(异常表)、constants(常量)等constant pool常量池。Annotations注解。方法计数器。记录方法执行的次数,用于辅助JIT的决策。
在线Java分析工具
www.javamex.com 中提供了许多面向对象的工具:比如classmexer计算对象的大小。
参考: 《深入理解JAVA虚拟机》 Java指针压缩
最后更新于