Redis入门
AP高性能缓存,or,集中式存储。
数据结构
通用规则:
create if not exists:如果容器不存在,那就创建一个,再进行操作。
drop if no elements:如果容器里的元素没有了,那么立即删除容器,释放内存。
可以以对象为单位,设置过期时间。
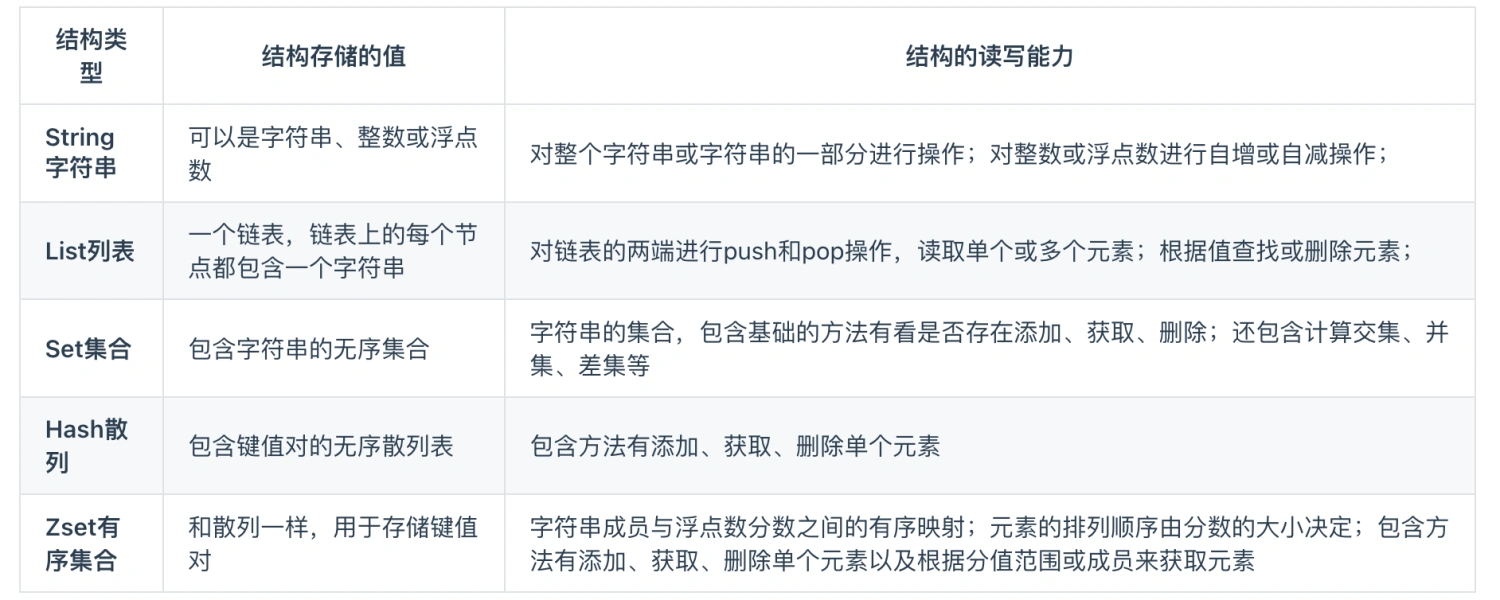
String
常用指令
普通字符串的基本操作:
批量设置 :
计数器(字符串的内容为整数的时候可以使用):
过期(默认为永不过期):
不存在就插入:
list
可以理解为双向链表,常用来做异步队列使用,一般不用作栈。 lpush key value lpop key ...
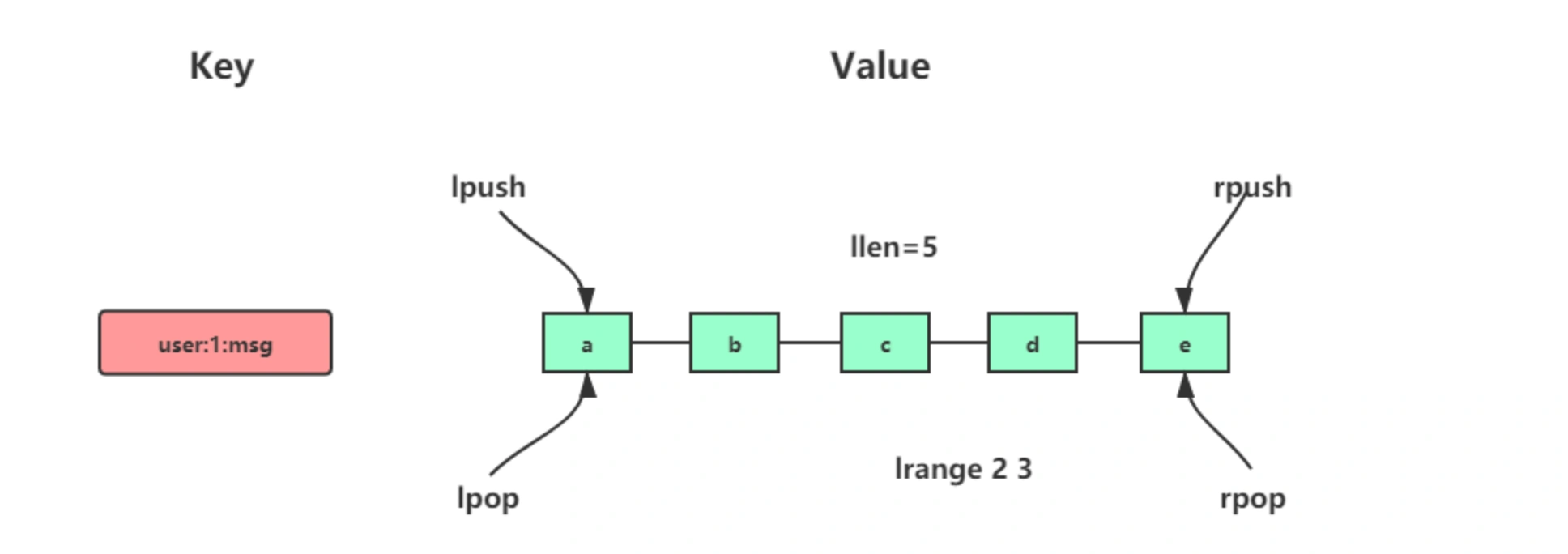
LRANGE key start stop 返回列表key中指定区间内的元素,区间以偏移量start和stop指定,从0开始
实现原理
实际上是“快速链表”(quicklist)结构。首先在列表元素较少的情况下,会使用一块连续的内存存储,这个结构是 ziplist(压缩列表)。它将所有的元素彼此紧挨着一起存储,分配的是一块连续的内存。当数据量比较多的时候才会改成 quicklist。也就是将多个 ziplist 使用双向指针串起来使用。
ziplist: 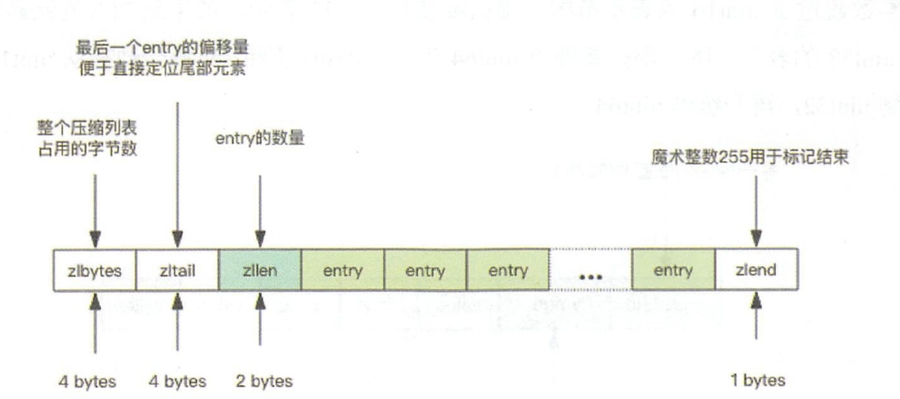
hash
无序字典。Redis 的字典的值只能是字符串。
常用命令
实现原理
Hash 类型的底层数据结构是由压缩列表或哈希表实现的:
如果哈希类型元素个数小于
512个(默认值,可由hash-max-ziplist-entries配置),所有值小于64字节(默认值,可由hash-max-ziplist-value配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构;如果哈希类型元素不满足上面条件,Redis 会使用哈希表作为 Hash 类型的 底层数据结构。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
渐进式rehash
rehash: 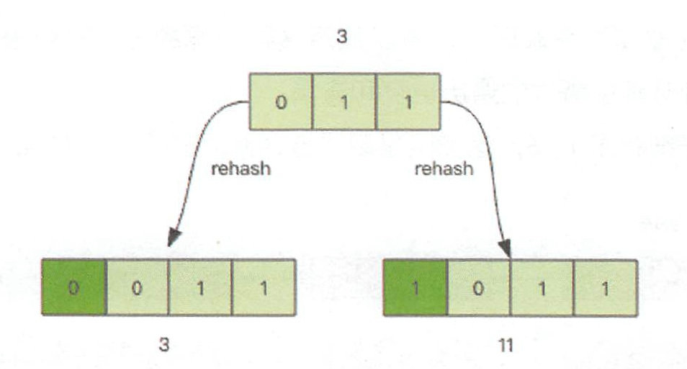
渐进式rehash:在 rehash 的同时,保留新旧两个 hash 结构。在定时任务中以及后续对 hash 的指令操作中,渐渐地将旧数组中挂接的元素迁移到新数组上。
Redis 的定时任务会记录在一个被称为“最小堆”的数据结构中。在每个循环周期里,Redis 都会对最小堆里面已经到时间点的任务进行处理。处理完毕后,将最快要执行的任务还需要的时间记录下来,这个时间就是 select 系统调用的timeout 参数。
set
Set 类型的底层数据结构是由哈希表或整数集合实现的,支持并(sunion)交(sinter)差(sdiff)等操作。
整数集合: 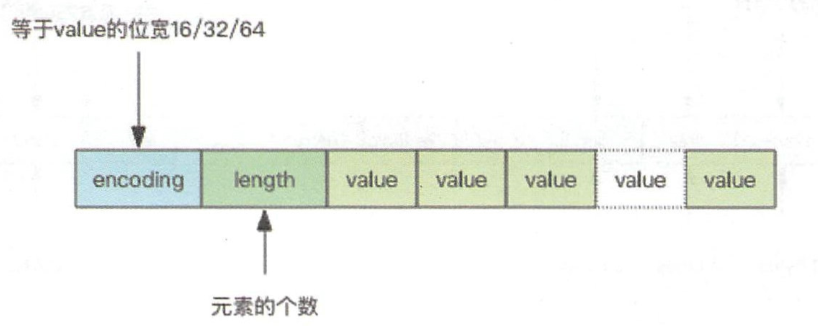
常用命令
Set运算操作:
Zset
有序列表。内部实现类似于跳表。相比于传统set,多了一个排序属性 score,也就是说,每个存储元素包含两个单元:<元素值 value,排序值 score>
常用命令
Zset 运算操作(相比于 Set 类型,ZSet 类型没有支持差集运算):
HyperLogLog
PV(访问量): 即Page View, 即页面浏览量,用户每次刷新都被计算一次。 UV(独立访客):即Unique Visitor,访问网站的一台电脑客户端为一个访客。
HyperLogLog 是一种用于统计基数 的数据集合类型,提供不精确的去重计数方案,标准误差是 0.81%,可用于满足 UV 统计需求。提供集合类似的操作:
pfadd(类似于 sadd ),增加计数。
pfcount (类似于 scard ),获取计数值。
pfmerge(类似于 sunion),用于将多个 pf 计数值累加形成新的 pf 值。
实现原理
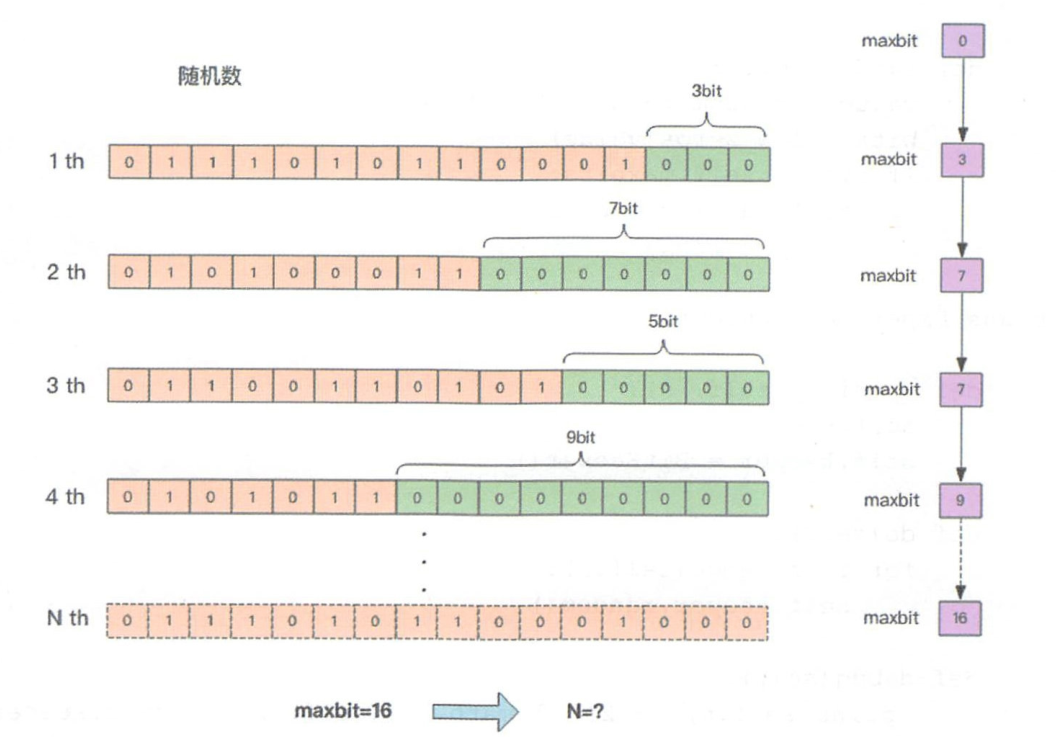
图解:给定一系列的随机整数,维护低位连续零位的最大长度 K (图中 maxbit ),通过这个 K 值估算出随机数的数量 N 。因为,$N = 2^K$。为了减少误差,引入不同权值,由此分 16384 个桶,使用调和平均(为了平滑离群值)计算平均值。
每个桶的 maxbits 需要 6 个 bit 存储,最大可以表示 maxbits=63,总共占用内存即$16384 * 6 / 8 = 12KB$
实际应用
布隆过滤器
由于HyperLogLog没有提供contains方法,不好确定值是否已经在set内,因此,引入布隆过滤器,在起到稍微不精确的去重作用的同时,在空间上节省 90% 以上。提供的接口:
bf.(m)add,添加(多个)元素bf.(m)exists,查询(多个)元素是否存在。可能误判不存在的元素为存在bf.reserve(key, error_rate, initial_size),显式创建布隆过滤器
内部实现:一个大型的位数组和几个不一样的无偏 hash 函数(即 hash 分配较为均匀)。每次add,将几个函数对应算得的哈希索引置位 1 ;判断exists时,判断这些位是否均为 1 。例如下图是一个位图数组长度为 8,哈希函数 3 个的布隆过滤器,当判断x是否存在时,判断1 4 6位是否全为 1 即可。
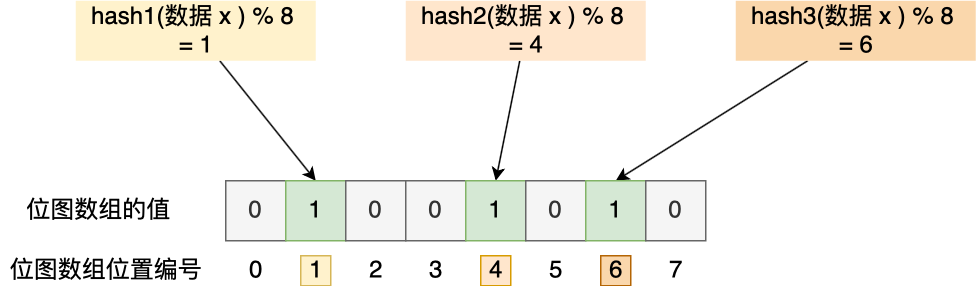
存在哈希冲突的可能性。因此,对于没见过的元素,可能误判为存在。也就是说,查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。
空间占用计算公式 ( l - 位数组长,n - 哈希函数数, k - 错误率参数) $k = 0.7 * (l/n)$ $f=0.6185^{l/n}$ 如果实际元素数超出配置的预计数,引入 t 为超出后的倍数,则 $f = (1-0.5^t)^k$ 错误率上升较为陡峭。
延时队列
对于单 消费者、可靠性要求不极高的消息队列要求,Redis可以较为轻量地实现延时队列。如,list就可作为异步消息队列使用。其中,如果只适用lpop(配合睡眠)有一个问题,如果队列空了,客户端就会陷入 pop 的死循环,即空轮询。blpop brpop 在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,立刻醒过来。
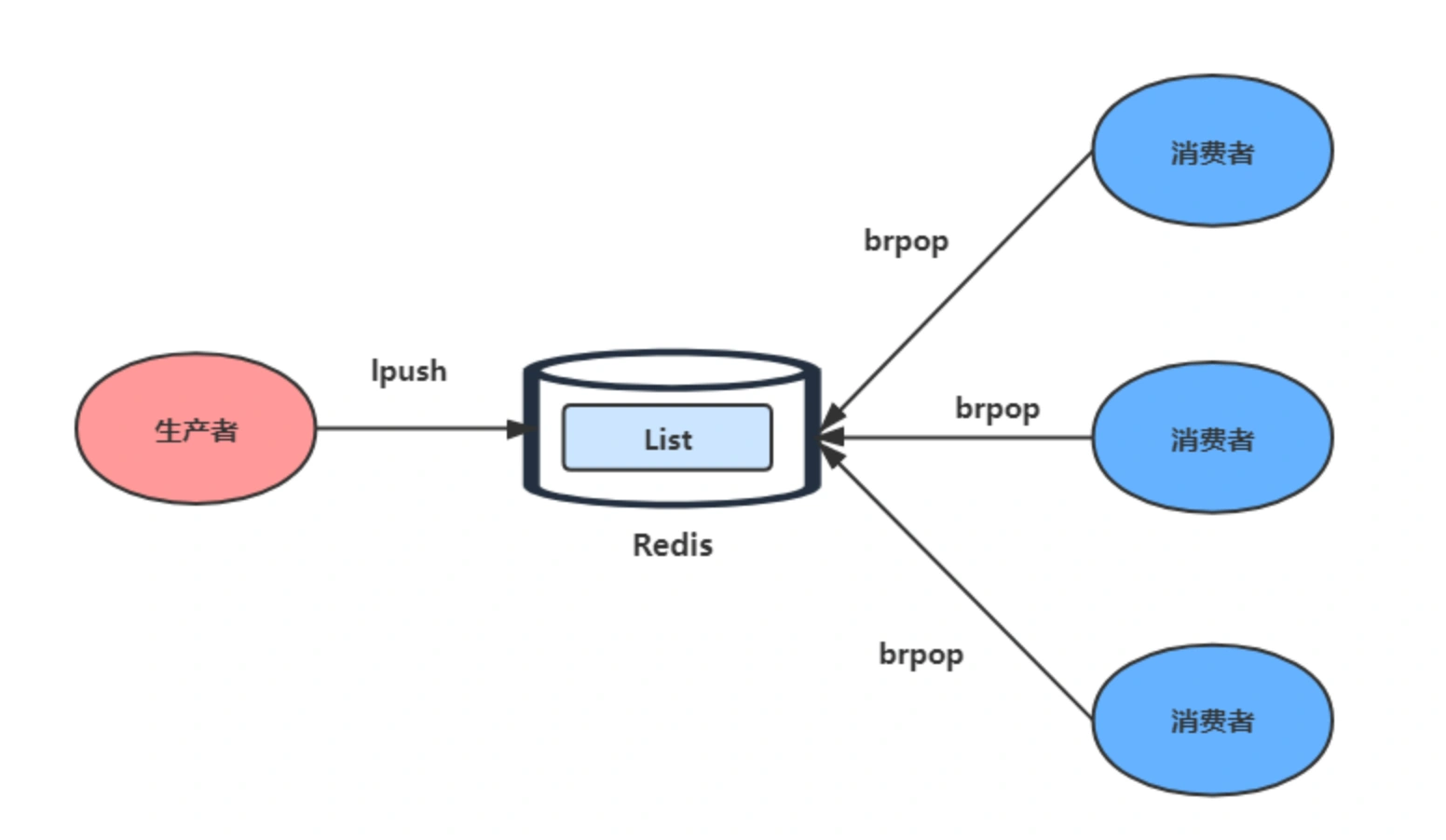
为保证可靠性,List 类型提供了 BRPOPLPUSH 命令,这个命令的作用是让消费者程序从一个 List 中读取消息,同时,Redis 会把这个消息再插入到另一个 List(可以叫作备份 List)留存。
消息保序:使用 LPUSH + RPOP;
阻塞读取:使用 BRPOP;
重复消息处理:生产者自行实现全局唯一 ID;
消息的可靠性:使用 BRPOPLPUSH
延时队列也可以通过 Redis 的 zset (有序列表)来实现。将消息序列化成一个字符串作为 zset 的 value ,消息的到期处理时间作为 score 。然后用多个线程轮询 zset 获取到期的任务进行处理。
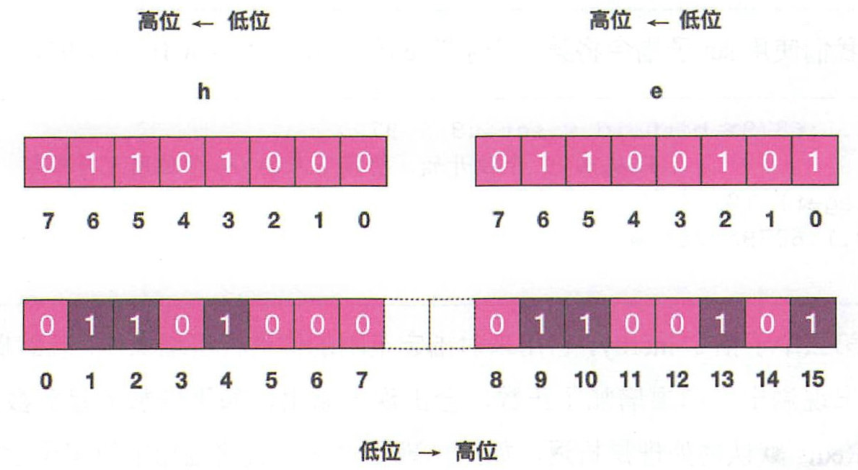
位图
可以使用普通的 get/set 直接获取和设置整个位图,也可以使用位图操作getbit/setbit 等将 byte 数组看成“位数组”来处理。注意,位数组的顺序和字符的位顺序是相反的。
Redis 提供了位图统计指令 bitcount (指定范围内 1 的总数)和位图查找指令 bitpos (指定范围内出现的第一个 0 或 1 )。如,bitpos w 1 2 2返回从第三个字符(Byte)算起,第一个 1 的位置,如返回17
bitfield 用于对一段位数组进行位操作,有三个子指令,分别是 get 、set 、incrby,但是最多只能处理 64 个连续的位。如,bitfield w get u4 0返回一个无符号数(u),代表从第 1 个位开始取 4 个位的值。
对于incrby子指令,溢出策略子指令 overflow,可供用户选择溢出行为(只影响接下来的第一条指令),默认是折返(wrap),还可以选择报错(fail),以及饱和截断(sat),即超过了范围就停留在最大或最小值。这条指令执行完后溢出策略会变成默认值折返(wrap)。
Redis 还提供了 BITOP operation(AND/NOT..) destkey key [key ...]这个指令用于对一个或者多个 key 的 Bitmap 进行位元操作。
限流策略
简单窗口限流 对于zset数据结构,value定义为时间戳。通过统计滑动窗口内的行为数量与阙值 max_count 进行比较就可以得出当前的行为是否被允许,可以移除时间窗口之前的行为记录。
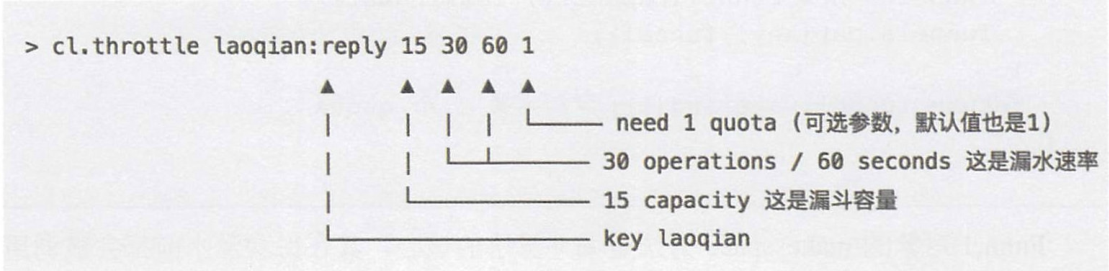
漏斗限流 Redis 4.0 提供了一个限流 Redis 模块( Redis-Cell ),提供了原子的限流指令——
cl.throttle返回[允许0/拒绝1] [capacity] [left_quota] [-1/如被拒绝,需要多长时间后再试] [漏斗完全空出来所需时间]
GeoHash
GeoHash 算法是业界位置信息服务(Location-Based Service,LBS)常用的地理位置距离排序算法,通过将二维的经纬度位置数据映射到一维的整数,并保持距离近的二维坐标映射到一维后的点之间距离也很接近,实现 LBS 服务中频繁使用的“搜索附近”的需求。Just Like:
10
11
可以对各个正方形继续二分切割,用更多的位数保持精确度。
在 Redis 里面,经纬度使用 52 位的整数进行base32编码,通过 zset 存储,value 是元素的 key,score 是 GeoHash 的 52 位整数值 。
scan
需要从 Redis 实例的成千上万个 key 中找出特定前缀的 key 列表,可以使用 keys 指令进行全遍历,但 Redis 是单线程程序,存在阻塞的风险。因此,引入scan指令,提供游标分步(不会阻塞线程)、limit参数功能。
由于是游标分步进行,遍历的过程中如果有数据修改,改动能不能遍历到是不确定的。单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零。依然,返回的结果可能会有重复。
除了可以遍历所有的 key 之外,还可以对指定的容器集合进行遍历。比如 zscan 遍历 zset 集合元素,hscan 遍历 hash 字典的元素。
实现原理
在 Redis 中所有的 key 都存储在一个很大的字典中。  考虑到避免字典扩容和缩容造成槽位的重复遍历或遗漏,scan采用高位进位加法来遍历。
考虑到避免字典扩容和缩容造成槽位的重复遍历或遗漏,scan采用高位进位加法来遍历。 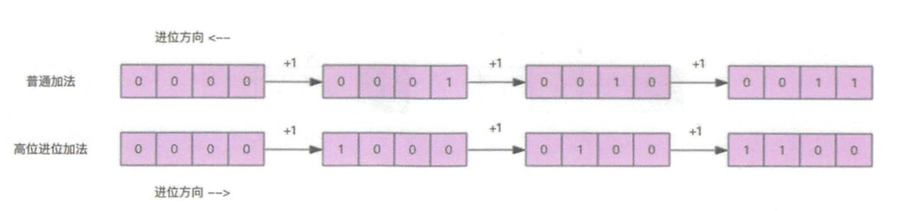
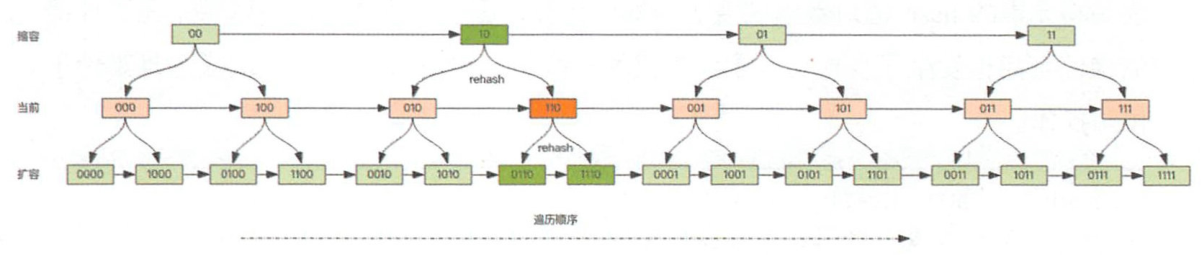
由于Redis 采用渐进式rehash,相对应地,scan也需要同时扫描新旧槽位,然后将结果融合后返回给客户端。
事务
指令:
multi- 指示事务的开始exec- 指示事务的执行discard指示事务的丢弃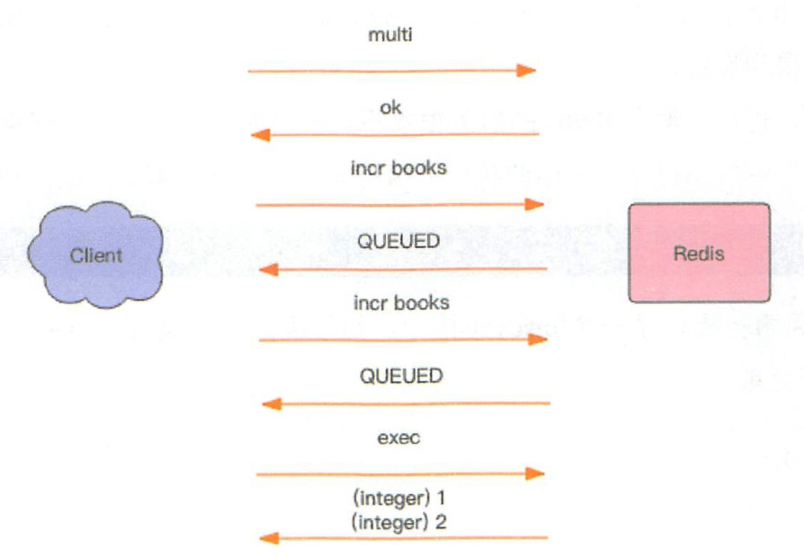
上图是一种事务创建和执行方式。实际上,为了减少网络IO,一般结合pipeline,一次传递整个事务。比如说
Redis的事务根本不具备“原子性”(如果中间指令出现异常,是跳过,后续指令继续执行),而仅仅是满足了事务的“隔离性”中的串行化(不被其他事务打断的权利)。
为避免并发冲突,可能需要悲观锁(分布式锁)。Redis 提供了watch的机制,这是一种乐观锁。要求在 multi 前添加watch,服务器收到了 exec 指令要顺序执行缓存的事务队列时,Redis 会检查关键变量自 watch 之后是否被修改了(包括当前事务所在的客户端)。如果关键变量被修改过,exec 指令就会返回 NULL 回复,告知客户端执行失败,这个时候客户端一般捕捉WatchError选择重试。
过期删除策略
常用指令
设置 key 过期时间的命令一共有 4 个:
expire <key> <n>:设置 key 在 n 秒后过期,比如 expire key 100 表示设置 key 在 100 秒后过期;pexpire <key> <n>:设置 key 在 n 毫 秒后过期,比如 pexpire key2 100000 表示设置 key2 在 100000 毫秒(100 秒)后过期。expireat <key> <n>:设置 key 在某个时间戳(精确到秒)之后过期,比如 expireat key3 1655654400 表示 key3 在时间戳 1655654400 后过期(精确到秒);pexpireat <key> <n>:设置 key 在某个时间戳(精确到毫秒)之后过期,比如 pexpireat key4 1655654400000 表示 key4 在时间戳 1655654400000 后过期(精确到毫秒)
在设置字符串时,也可以同时对 key 设置过期时间,共有 3 种命令:
set <key> <value> ex <n>:设置键值对的时候,同时指定过期时间(精确到秒);set <key> <value> px <n>:设置键值对的时候,同时指定过期时间(精确到毫秒);setex <key> <n> <valule>:设置键值对的时候,同时指定过期时间(精确到秒)。ttl key查看 key 离过期时间还剩多少。返回-1表示永不过期。persist key:取消 key 的过期时间
Redis 会将每个设置了过期时间的 key 放入一个独立的过期字典中,以后会定时遍历这个字典来懒删除到期的 key。当查询一个 key ,先查过期字典,比对该 key 的过期时间,过期则进行懒删除。
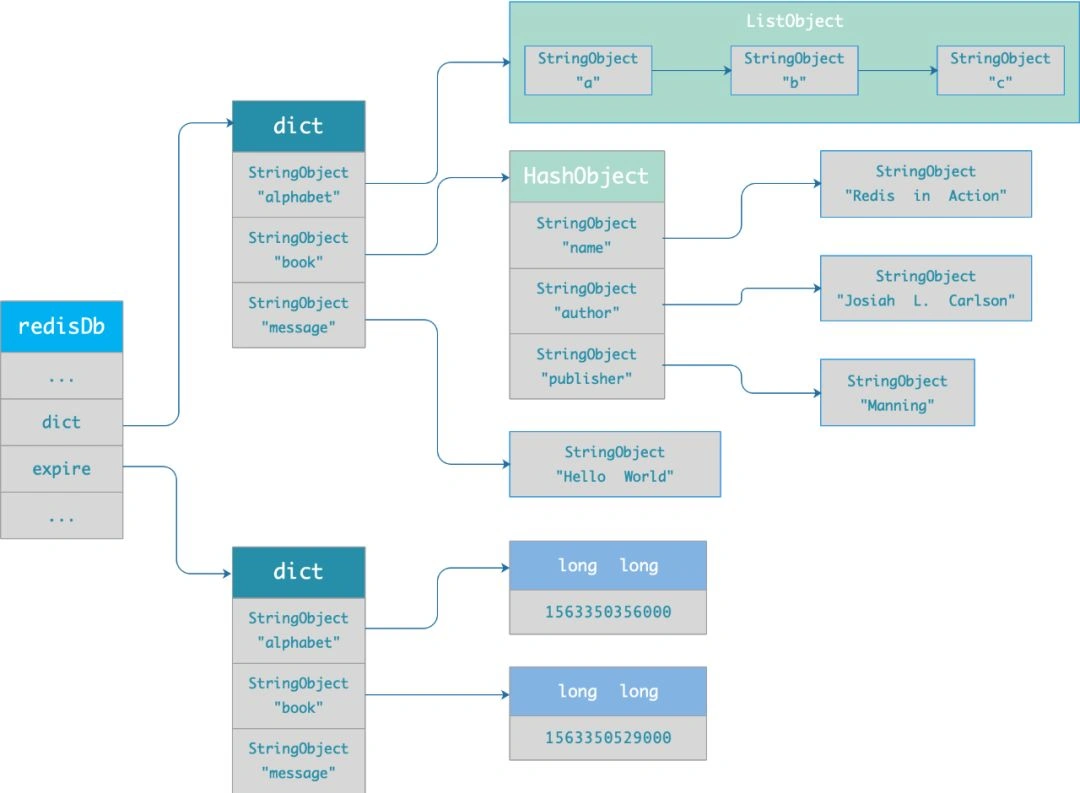
三种过期删除策略
定时删除:在设置 key 的过期时间时,同时创建一个定时事件,当时间到达时,由事件处理器自动执行 key 的删除操作。 内存友好,CPU不友好。
惰性删除:不主动删除过期键,每次从数据库访问 key 时,都检测 key 是否过期,如果过期则删除该 key。 CPU友好,内存不友好。
定期删除:每隔一段时间「随机」从数据库中取出一定数量的 key 进行检查,并删除其中的过期key。 限制删除操作执行的时长和频率。
Redis 选择「惰性删除+定期删除」这两种策略配合使用:
Redis 在访问或者修改 key 之前,都会调用
expireIfNeeded函数对其进行检查。如果过期,则删除该 key(异步/同步,根据lazyfree_lazy_expire参数配置决定(Redis 4.0+),返回 null 客户端;默认每秒进行 10 次(
redis.conf:hz)过期检查一次数据库,每轮抽查时,会随机选择 20 个 key 判断是否过期。如果本轮检查的已过期 key 的数量,超过 5 个(占比大于1/4),重复,否则等待下一轮检查。为保证定期删除不会出现循环过度,导致线程卡死,为此增加了定期删除循环流程的时间上限,默认不会超过 25ms。
缓存雪崩
25ms的阻塞其实也不短。为避免缓存雪崩(大量数据同时过期),开发人员通常会给过期时间设置一个随机波动。 另有其他方式处理缓存雪崩问题:
带超时时间的互斥锁:将缓存构建阶段放入临界区。未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。
双key策略:主key(会设置过期时间)、备key(不过期,理解为备份)指向同一个value。当业务线程访问不到主 key的缓存数据时,就直接返回备 key的缓存数据。当主 key 过期了,有大量请求获取缓存数据的时候,直接返回备 key 的数据,这样可以快速响应请求,而不用因为 key 失效而导致大量请求被锁阻塞住,后续再通知后台线程,重新构建主 key 的数据。
后台更新缓存:缓存也不设置有效期,而是让缓存在前台“永久有效”,将更新缓存的工作交由后台线程定时更新。为淘汰缓存,后台线程可以兼顾检测缓存有效性,或由业务线程消息队列通知,加载缓存。此机制也适合上线前的缓存预热。
缓存击穿是缓存雪崩的一个子集,如果缓存中的某个热点数据过期了,此时大量的请求访问了该热点数据,就无法从缓存中读取,直接访问数据库,数据库很容易就被高并发的请求冲垮。可以使用互斥锁方案、后台更新缓存方案应对。
内存淘汰策略
当 Redis 的运行内存达到最大运行内存(redis.conf:maxmemory <bytes>),会触发内存淘汰策略maxmemory-policy。
Redis 内存淘汰策略共有八种,这八种策略大体分为不进行数据淘汰 和 进行数据淘汰 两类策略。
不进行数据淘汰的策略
noeviction(Redis3.0之后,默认的内存淘汰策略) :它表示当运行内存超过最大设置内存时,不淘汰任何数据,这时如果有新的数据写入,则会触发 OOM,但是如果没用数据写入的话,只是单纯的查询或者删除操作的话,还是可以正常工作。
del会直接释放对象。对于大key,可以通过unlink懒删除key,即切断其可达性,再异步删除。类似地,对于清空数据库,flushdb和flushall后接async,也可以异步化。
进行数据淘汰的策略
在设置了过期时间的数据中进行淘汰:
volatile-random:随机淘汰设置了过期时间的任意键值;
volatile-ttl:优先淘汰更早过期的键值。
volatile-lru(Redis3.0 之前,默认的内存淘汰策略):淘汰所有设置了过期时间的键值中,最久未使用的键值;
volatile-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰所有设置了过期时间的键值中,最少使用的键值;
在所有数据范围内进行淘汰:
allkeys-random:随机淘汰任意键值;
allkeys-lru:淘汰整个键值中最久未使用的键值;
allkeys-lfu(Redis 4.0 后新增的内存淘汰策略):淘汰整个键值中最少使用的键值。
Redis-LRU
Redis 实现的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是在 Redis 的对象结构体中添加一个额外的字段,用于记录此数据的最后一次访问时间。当 Redis 进行内存淘汰时,会使用随机采样的方式来淘汰数据,默认随机取 5 个值(可配置),然后淘汰最久没有使用的那个。此方法会造成缓存污染。
Redis-LFU
LFU 算法相比于 LRU 算法的实现,多记录了数据的访问频次。对于原本的24位时间戳,unsigned lru:24; 改为存储Last Decrement Time:16 + logistic Counter:8),即访问时间戳和访问频次(每个新加入的 key 的logc 初始值为 5,会随时间递减)的组合。
每次 key 被访问时,会先对 logc 做一个衰减操作,衰减值跟前后访问时间差有关,时间差越大,衰减值就越大,其速度由lfu-decay-time <minute>参数配置。衰减阶段后,再对 logc 进行增加操作,增加量按照一定概率进行,logc 越大的 key,它的 logc 就越难再增加(由lfu-log-factor配置,值越大,logc 增长越慢)。
线程模式
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发送数据给客户端」这个过程是由一个线程(主线程)来完成的,这也是我们常说 Redis 是单线程的原因。
在Redis6.0之前的单线程模式如下图: 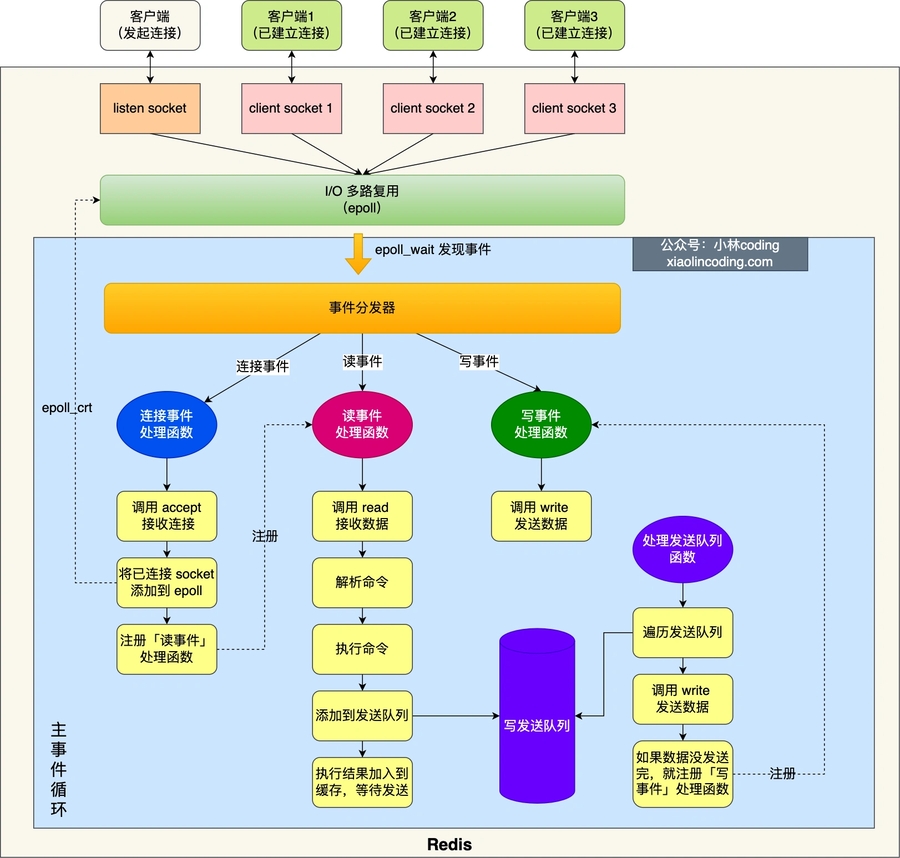
但是,Redis 程序并不是单线程的,Redis 在启动的时候,是会启动后台线程(BIO)的:
Redis 在 2.6 版本,会启动 2 个后台线程,分别处理关闭文件、AOF 刷盘这两个任务;
Redis 在 4.0 版本之后,新增了一个新的后台线程
lazyfree,用来懒删除(异步释放 Redis 内存)。例如执行 unlink key / flushdb async / flushall async 等命令。
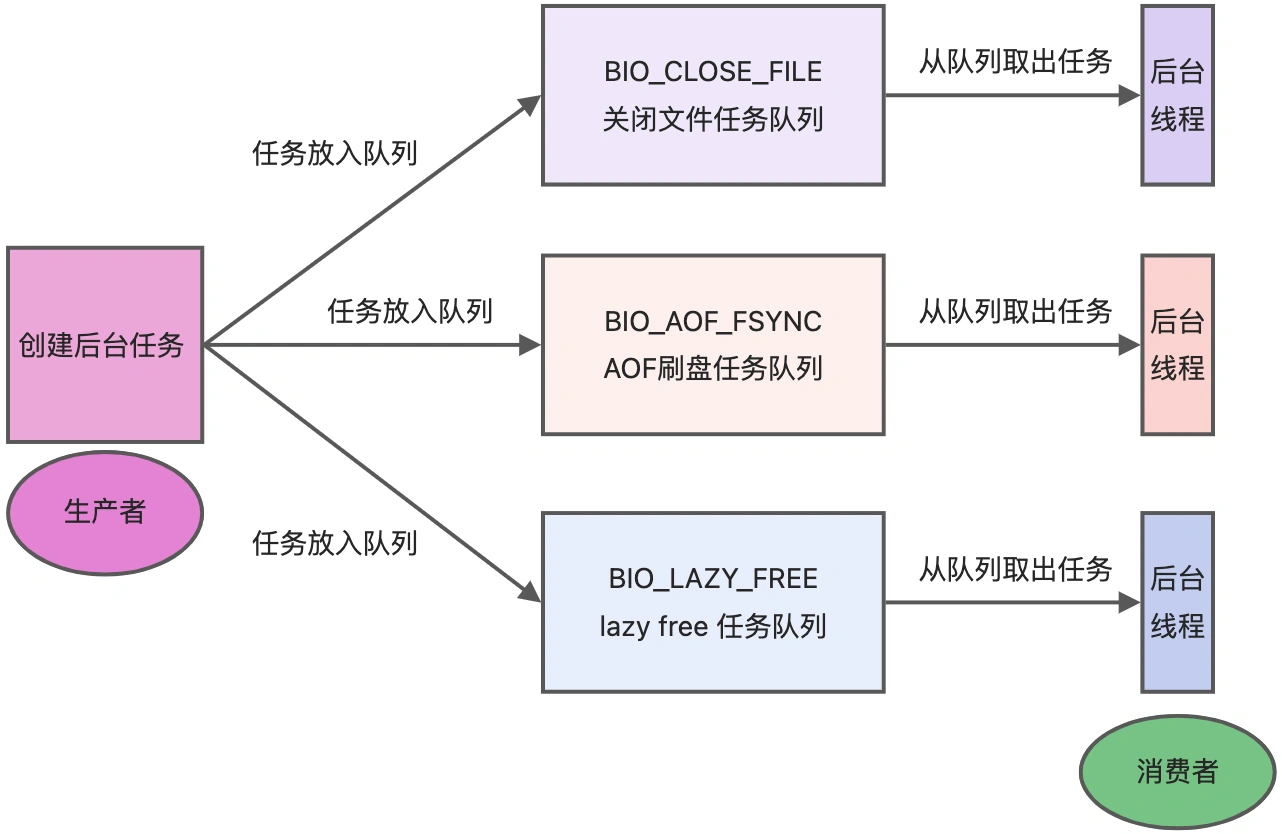
Redis 6.0 版本之后,引入多线程IO处理网络请求。此后,Redis 在启动的时候,默认情况下会创建 6 个线程:
Redis-server : Redis的主线程,主要负责执行命令;
bio_close_file、bio_aof_fsync、bio_lazy_free:三个后台线程,分别异步处理关闭文件任务、AOF刷盘任务、释放内存任务;
io_thd_1、io_thd_2、io_thd_3:三个 I/O 线程,io-threads 默认是 4 ,所以会启动 3(4-1)个 I/O 多线程,用来分担 Redis 网络 I/O 的压力。
参考: 《Redis深度历险》 https://xiaolincoding.com/redis
最后更新于