操作系统
IO
文件一致性
当前 Linux 下以两种方式实现文件一致性:
Write Through(写穿):向用户层提供特定接口,应用程序可主动调用接口来保证文件一致性;
Write back(写回):系统中存在定期任务(表现形式为内核线程),周期性地同步文件系统中文件脏数据块,这是默认的 Linux 一致性方案;
上述两种方式最终都依赖于系统调用,主要分为如下三种系统调用:
fsync(intfd)
fsync(fd):将 fd 代表的文件的脏数据和脏元数据全部刷新至磁盘中。
fdatasync(int fd)
fdatasync(fd):将 fd 代表的文件的脏数据刷新至磁盘,同时对必要的元数据刷新至磁盘中,这里所说的必要的概念是指:对接下来访问文件有关键作用的信息,如文件大小,而文件修改时间等不属于必要信息
sync()
sync():则是对系统中所有的脏的文件数据元数据刷新至磁盘中
同步/异步;阻塞/非阻塞
同步/异步:这个活由不由你来干? 阻塞/非阻塞:这个活干完之前,你能不能干其他的活?
实际例子: 假设你去咖啡店买咖啡。
同步阻塞: 你点了一杯咖啡,站在柜台前等待咖啡做好,期间你什么都不做,直到咖啡做好为止。
异步阻塞: 这是一个有点奇怪的场景。假设你点了咖啡后,你坐下等待咖啡完成。店员会在咖啡完成时通知你,但在此期间,你坐在那里什么也不做。
同步非阻塞: 你点了咖啡后,不断地问店员咖啡是否做好。你没有停下来等待,而是保持活跃(可能在做其他事情),但你需要不断地检查咖啡的状态。
异步非阻塞: 你点了咖啡后,就去做其他事情(如读书、浏览手机等)。当咖啡做好时,店员会叫你。你不需要检查咖啡何时做好,因为你知道会被通知。 在计算领域中,我们可以认为: - 同步: 函数或方法调用,它返回时,结果必须是已知的。 - 异步: 函数或方法调用,它返回时,结果可能还不是已知的。它在未来的某个时间点提供结果,通常通过回调、事件、信号等方式。 - 阻塞: 如果结果不可用,调用者必须等待。 - 非阻塞: 如果结果不可用,调用者可以立即返回并做其他事情。
NIO
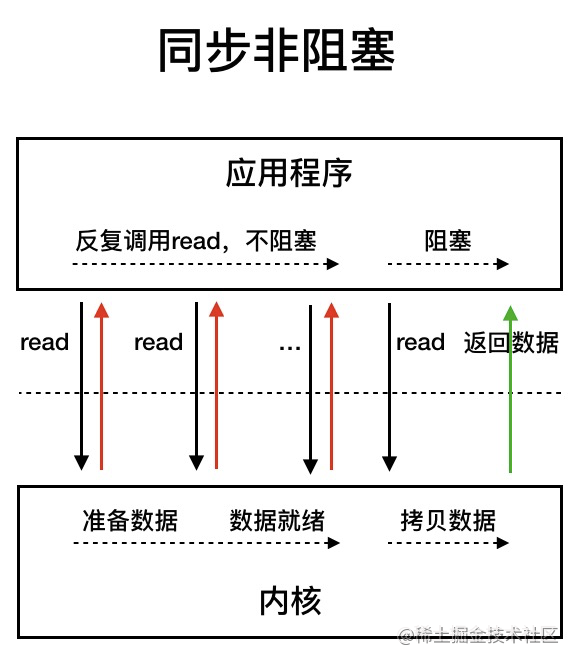
也就是说,在内核数据没有准备就绪时,应用可以轮询是否就绪(而不是阻塞等待)。得到是就绪后,就阻塞等着从内核把数据进行拷贝。
详见 Java NIO浅析 - 美团技术团队 (meituan.com)
一个 Channel 对应一个 Buffer。
Selector 对应一个线程,一个线程对应多个 Channel,多个 Channel 根据多路复用规则,和根据不同的事件(程序切换到那个 Channel 是由事件决定的),在各个通道上切换。通过 Buffer 进行数据的读取和写入。
Buffer 就是一个内存块,底层是有一个数组。
中断
中断是系统用来响应硬件设备请求的一种机制。中断处理程序要短且快,在响应中断时,可能还会「临时关闭中断」,也就是屏蔽。
Linux 系统为了解决中断处理程序执行过长和中断丢失的问题,将中断过程分成了两个阶段,分别是「上部和下部」。
上部(硬中断)用来快速响应中断,一般会暂时屏蔽中断,主要负责处理跟硬件紧密相关或者时间敏感的事情。比如网卡进行DMA传输,上部主要是禁止网卡中断,避免频繁硬中断,而降低内核的工作效率。接着,内核会触发一个软中断,把一些处理比较耗时且复杂的事情,交给「软中断处理程序」去做,也就是中断的下部。
下部(软中断)用来延迟处理上部未完成的工作,一般以「内核线程」的方式运行。如刚刚的网卡DMA传输为例,延迟执行网络数据的解析和处理,即按照网络协议栈把数据送给应用程序。
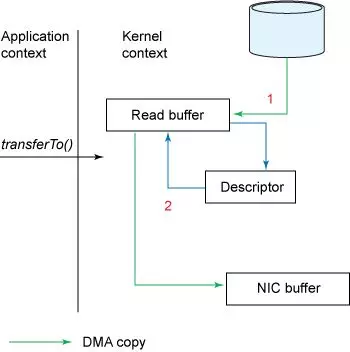
零拷贝
在 OS 层面上的 Zero-copy 通常指避免在 用户态 与 内核态 之间来回拷贝数据。
常见的零拷贝思路主要有三种:
直接 I/O:数据直接跨过内核,在用户地址空间与 I/O 设备之间传递,内核只是进行必要的虚拟存储配置等辅助工作;
避免内核和用户空间之间的数据拷贝:当应用程序不需要对数据进行访问时,则可以避免将数据从内核空间拷贝到用户空间;
写时复制(mmap):数据不需要提前拷贝,而是当需要修改的时候再进行部分拷贝。
磁盘
 完成一次磁盘 IO,需要经过寻道、旋转和数据传输三个步骤。顺序写文件,基本减少了磁盘寻道和旋转的次数。
完成一次磁盘 IO,需要经过寻道、旋转和数据传输三个步骤。顺序写文件,基本减少了磁盘寻道和旋转的次数。
内存管理
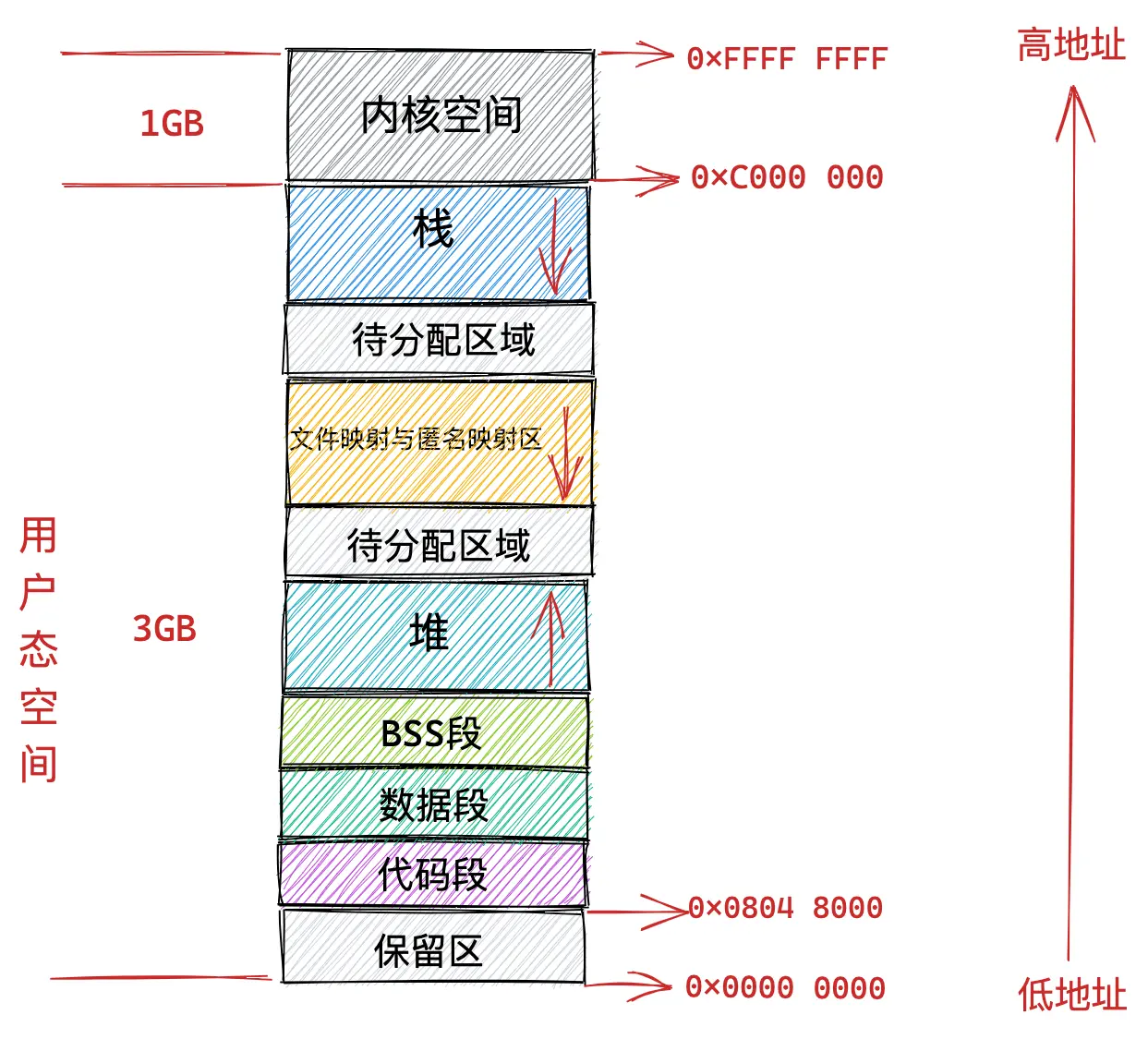
不可访问的保留区:NULL指向。
在64位中,高 16 位空闲地址造成 canonical address 空洞。
在64位中,代码段跟数据段的中间还有一段不可以读写的保护段,它的作用是防止程序在读写数据段的时候越界访问到代码段,这个保护段可以让越界访问行为直接崩溃,防止它继续往下运行。
内核中采用了一个叫做内存描述符的 mm_struct 结构体来表示进程虚拟内存空间的全部信息。
分配
malloc 申请内存的时候,会有两种方式向操作系统申请堆内存。这两种方式是为了减少碎片。
方式一:需要分配的内存小于 128 KB,通过 brk() 系统调用从堆分配内存。此方式通过 free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用;
方式二:需要分配的内存大于 128 KB,通过 mmap() 系统调用在文件映射区域分配内存。此方式通过 free 释放内存的时候,会把内存归还给操作系统,内存得到真正的释放。
此外, malloc 返回给用户态的内存起始地址比进程的堆空间起始地址多了 16 字节,用于保存该内存块的描述信息,比如该内存块的大小。
虚拟内存
64 位系统下,虚拟地址的格式为:全局页目录项(9位)+ 上层页目录项(9位)+ 中间页目录项(9位)+ 页表项(9位)+ 页内偏移(12位)。 共 48 位。
进程换页表
进程的换页表是当进程的上下文切换发生时的一个关键步骤。页表是存储在内存中的数据结构,用于虚拟地址到物理地址的转换。每个进程都有其自己的页表。当进程进行上下文切换时,相关的页表也需要被切换。 以下是进程换页表的基本步骤:
保存当前进程状态:首先,操作系统会保存当前运行进程的状态,这包括程序计数器、寄存器值等。
选择下一个进程:调度算法会决定下一个要执行的进程。
加载新的页表:
页表基址寄存器(PTBR)被加载为新进程的页表的物理地址。这是告诉内存管理单元(MMU)新的页表在哪里的关键步骤。
页表长度寄存器(PTLR)也可能被设置,它定义了页表的大小。
刷新TLB:TLB(Translation Lookaside Buffer)是一个小的硬件缓存,它存储最近的虚拟地址到物理地址的映射。当页表被切换时,TLB的内容可能已经过时,因此它需要被刷新或无效化。
恢复新进程状态:操作系统恢复新进程的状态,这包括程序计数器、寄存器值等。
执行新进程:处理器开始执行新选定的进程。
进程的上下文切换,尤其是更换页表,是一个相对耗时的操作,因此操作系统通常会尽量最小化上下文切换的数量。
Linux
守护进程
Docker 运行时包括一个名为
dockerd的长时间运行的守护进程。
0 号进程(swapper 或 scheduler):
通常被称为“idle”任务。这是内核启动后创建的第一个进程。
它不是通过 fork() 创建的,因为在它运行之前没有其他进程。
该进程执行所有可用 CPU 的任务调度。
在任务列表中,其 PID 为 0。
1 号进程(init 或 systemd):
在早期的 Linux 发行版中和 SysV 风格的系统中,
init是 1 号进程。在许多现代 Linux 发行版中(如 Fedora,CentOS 7+ 和 Ubuntu 15.04+),
systemd替代了init作为 1 号进程。它是所有用户级进程的父进程。当某个进程的父进程结束时,该进程由 init 接管。
它负责启动和管理系统上的所有其他守护进程。
孤儿进程(父进程比子进程先退出)的归宿:操作系统会将孤儿进程的父进程改为1号进程。
子进程在完成了其任务后,但其父进程尚未调用
wait或waitpid等系统调用来获取子进程的退出状态信息,子进程会变成僵尸进程:退出状态信息仍然会被内核保留,但其资源(如进程表项和内存)不会被完全释放。
Shell
内置变量
$0
当前脚本的名称。
echo $0 将输出脚本的名称。
$1, $2, … $n
传递给脚本或函数的参数。
如果脚本使用 ./script.sh arg1 arg2 运行,echo $1 将输出 arg1。
$#
传递给脚本或函数的参数的数量。
echo $# 将输出参数的数量。
$*
所有的参数列表。"$*" 将所有参数视为一个单一的字符串。
如果脚本使用 ./script.sh arg1 arg2 运行,echo $* 将输出 arg1 arg2。
$@
所有的参数列表。但每个参数是独立的。
如果脚本使用 ./script.sh arg1 arg2 运行,echo "$@" 将输出 arg1 arg2。
$?
上一个命令执行后的退出状态或错误代码。成功为0,非零则为失败。
ls /nonexistentdir; echo $? 将输出一个非零值,因为 ls 命令失败。
$$
当前脚本的进程ID。
echo $$ 将输出脚本的进程ID。
$!
最后一个在后台执行的命令的进程ID。
sleep 10 & echo $! 将输出 sleep 命令的进程ID。
$_
最后一个命令的最后一个参数。
ls /etc; echo $_ 将输出 /etc。
$-
显示当前使用的 Shell 和它的参数,或者显示 Shell 启动时的命令行参数。
echo $- 通常会输出例如 himBH,这取决于当前 shell 的标志。
容器化
Kubernetes
调度: 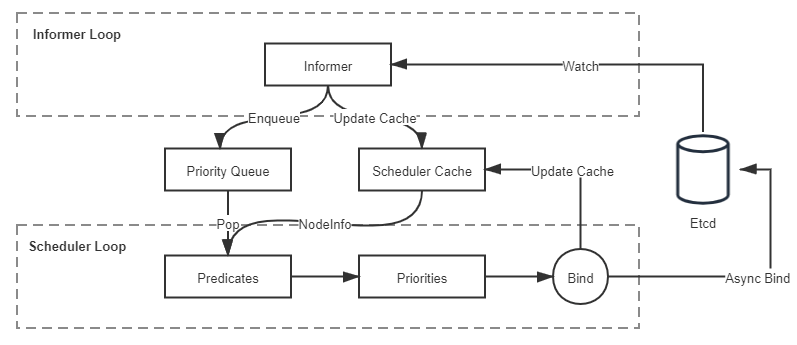
状态共享的双循环中第一个控制循环可被称为“Informer Loop”,它是一系列Informer的集合,这些 Informer 持续监视 Etcd 中与调度相关资源(主要是 Pod 和 Node)的变化情况,一旦 Pod、Node 等资源出现变动,就会触发对应 Informer 的 Handler。Informer Loop 的职责是根据 Etcd 中的资源变化去更新调度队列(Priority Queue)和调度缓存(Scheduler Cache)中的信息,譬如当有新 Pod 生成,就将其入队(Enqueue)到调度队列中,如有必要,还会根据优先级触发上一节提到的插队和抢占操作。又譬如有新的节点加入集群,或者已有节点资源信息发生变动,Informer 也会将这些信息更新同步到调度缓存之中。
另一个控制循环可被称为“Scheduler Loop”,它的核心逻辑是不停地将调度队列中的 Pod 出队(Pop),然后使用 Predicate 算法进行节点选择。Predicate 本质上是一组节点过滤器(Filter),它根据预设的过滤策略来筛选节点,Kubernetes 中默认有三种过滤策略,分别是:
通用过滤策略:最基础的调度过滤策略,用来检查节点是否能满足 Pod 声明中需要的资源。譬如处理器、内存资源是否满足,主机端口与声明的 NodePort 是否存在冲突,Pod 的选择器或者nodeAffinity指定的节点是否与目标相匹配,等等。
卷过滤策略:与存储相关的过滤策略,用来检查节点挂载的 Volume 是否存在冲突(譬如将一个块设备挂载到两个节点上),或者 Volume 的可用区域是否与目标节点冲突,等等。在“Kubernetes 存储设计”中提到的 Local PersistentVolume 的调度检查,便是在这里处理的。
节点过滤策略:与宿主机相关的过滤策略,最典型的是 Kubernetes 的污点与容忍度机制(Taints and Tolerations),譬如默认情况下 Kubernetes 会设置 Master 节点不允许被调度,这就是通过在 Master 中施加污点来避免的。之前提到的控制节点处于驱逐状态,或者在驱逐后一段时间不允许调度,也是在这个策略里实现的。
最后更新于