Raft-Consensus
PreKnow in Paper
Raft Basics
A Raft cluster contains several servers, five is a typical number
a server - three states:
leader,follower,candidate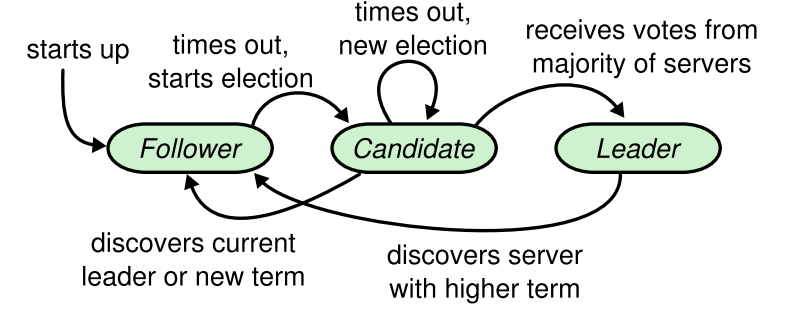
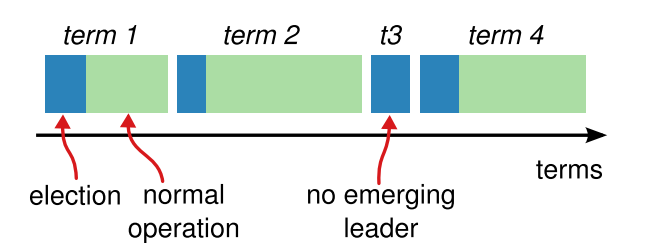
term: Raft ensures that there is at most one leader in a given term
Two RPC Types: (idempotent)
RequestVote RPC
AppendEntries RPCs:leader includes the index and term of the log entry to guarantee consistency
Server之间存在心跳检测
election timeout: Follower receives no communication over a period of time ->
elect new leaderSee State Trans Graph
Election restriction
the voter denies its vote if its own log is more up-to-date than that of the candidate.
log entries only flow in one direction, from leaders to followers, and leaders never overwrite existing entries in their logs.
Raft Summary Card

ALIAS IN ENV:
(Mention: 使用pretty print log, 会导致被[]包含的部分无法打印)
Lab2a
类间关系
Raft类对应的是每一个节点的信息,不是静态的。 -> 设定1:对于HeartBeat timeout(收)发起选举,此时rf.HeartBeatSentTime(发)视为心跳。根据状态的不同,或许可以为一个字段复用。不过为了少给自己添加不必要的混乱,还是继续用两个吧。
坑
Go语言的闭包会使对应的外部变量始终为外部变量(?),请看:
这里,闭包中的i会在执行时使用外部值,如你可能会遇到输出heartbeat 3/3 by leader 1.,这是因为外面的i已经完成了循环,使得函数内读取到i = len(rf.peers).
在这里配置了Pretty Debug,不得不说,工具还是很强大的。
Lab2b
到这里,遵循Locking Advice 就很重要了。
The locking rules a programmer chooses (e.g. "a goroutine must hold rf.mu when using rf.currentTerm or rf.state") are often called a "locking protocol".
->设定2:这里对于日志Append操作的发起,是结合心跳操作进行的。我想到了两个问题:1. 未处理完;2. 心跳太慢。这两个按照Figure 2或许有保护机制。
遇到过等锁死循环(i.e. dead loop)。
现在的心跳处理等锁太久,又出现多主节点的情况了。解决方式是重构了选举逻辑,参考下方prevote的引入
applyCh还不知道怎么使用,会一直block之。似乎没有处理Append异常的机制。 -> 设定3:
Apply对状态机的写入不仅限于leader,毕竟我们的目标就是状态机的一致性嘛。 (你倒是看看Figure 2啊.jpg 【ALL SERVERS!!】) 目前的设计是在requestHeartbeat时进行处理。但是Student's Guide to Raft 中似乎是在Raft里加了一层结构App进行操作的,不过也提到了这一操作不必straight away。我先试试...
引入PreVote
etcd减少无效RPC进行的优化。遇到的坑:
Never change FOLLOWER’S term in response to a PreVote
ETCD'S comment:
人话:确定是网络分区后新加入的旧LEADER,可以先发一条空消息,触发状态转移。
DEBUG剪影:
出现网络分区,如0 | 1 2。1/2分别完成prevote准备进行选举,但是不巧,1先开启了选举,在请求票的RPC到达2进行处理前,2也开始了选举并把票投给了自己,此时1和2都需要等待0回应,最后的结果是此次选举失败。重新开始的选举依旧受到此时间差的影响,在对方等待0回应时,无法得到它的票。导致无LEADER。(尚未解决)
Lab2C
助教提示,If a follower does not have prevLogIndex in its log, it should return with conflictIndex = len(log) and conflictTerm = None. 这里遇到了越界问题。这里注意循环的条件。 返回Term可以有一个特殊值,传递以下消息:发送方是outdated leader,需要退位了。
Lab2D
设定:既然[]LogEntry的[0]是占位符,我们不妨将其作为一个相对位置的哨兵,来保存最新 snapshot 的 lastLogTerm 信息。 但是还需要维护一个 LastLogIndex 变量,上面的设定会显得很乱。建议听从Lab的建议,设置结构体内的两个变量。
重构TODO: 一种有趣的方式是,rf.log 不直接声明为
[]LogEntry,而是`type Log {index0 , entries}
假设Leader A 与 节点 B 达成了完整的协议,也生成了快照,而 C 在较长时间的不在线中恢复。此时,C 不再能同步 A/B 已经生成快照部分的LogEntry。这个时候, InstallSnapshot 到落后的节点上面。落后节点收到 InstallSnapshot() 中的 snapshot 后,通过 rf.applyCh 发送给上层 service 。上层的 service 收到 snapshot 时,调用节点的 CondInstallSnapshot() 方法。
->出现apply乱序,怎么排查? 感觉是相差了一组SnapShot.但仔细一看,是【Snapshot】的内容,多次发送apply。如:"1 2 3 4 5 6 7 8 9 SHOT 10 11",1在初次接收和SHOT时,都apply了一次。 解决方案:状态变量更新过早。
最后更新于