DDIA-派生数据
存储和处理数据的系统可分为:
记录系统(真实数据系统),拥有数据的权威版本。
派生数据系统:获取数据并进行转换或处理的结果,可以认为是对现有信息的不同视角的复制。
我们来对下面三种类型系统进行考察:
服务(在线系统,online systems) 处理请求或指令。响应时间通常是衡量一个服务性能的最主要指标,且可用性通常也很重要。之前章节我们主要在讨论此类系统。
批处理系统(离线系统,offline systems) 一个批处理系统通常会接受大量数据作为输入,然后在这批数据上跑任务(job),进而产生一些数据作为输出。吞吐量通常是衡量批处理任务最主要指标。我们本章会主要围绕该类型系统进行讨论。
流式系统(近实时系统,near-real-time systems) 流式处理介于在线处理和离线处理(批处理)之间(因此也被称为近实时,near-real-time,或者准在线处理,nearline processing)。和批处理系统类似,但一个流式任务通常会在事件产生不久后就对其进行处理,而无需等足批单位的输入。
批处理系统
MapReduce 查询
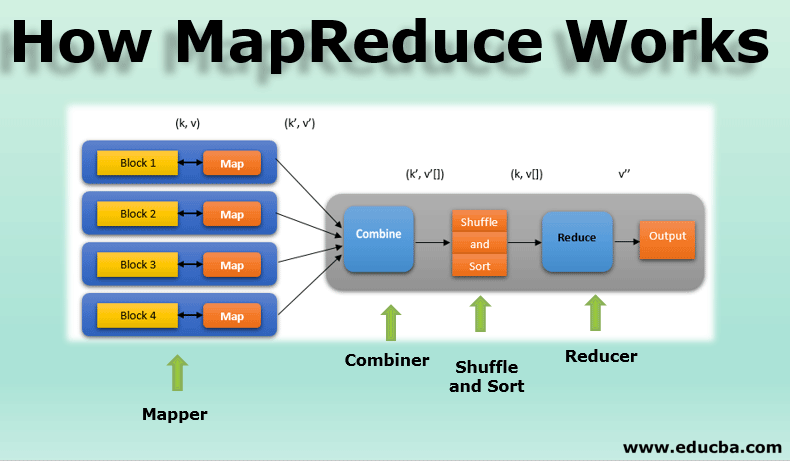
MongoDB 使用 MapReduce ,是一种介于
声明式:用户不必显式定义数据集的遍历方式、shuffle 过程等执行过程。
命令式:用户又需要定义针对单条数据的执行过程。 两者间的混合数据模型。
其中:
要求 Map 和 Reduce 是纯函数。即无任何副作用,在任意地点、以任意次序执行任何多次,对相同的输入都能得到相同的输出。因此容易并发调度。
非常底层、但表达力强大的编程模型。可基于其实现 SQL 等高级查询语言,如 Hive。
最后更新于