DDIA-补充拓展
存储
块存储
硬件分块,读写快
读写软件系统,如DB
文件存储
基于块存储的一层抽象,维护存储介质数据结构,便于按单元共享
人~~/Linux哲学~~
对象存储OSS
元数据独立 + 控制节点
其他计算机软件
密集型数据系统
levelDB
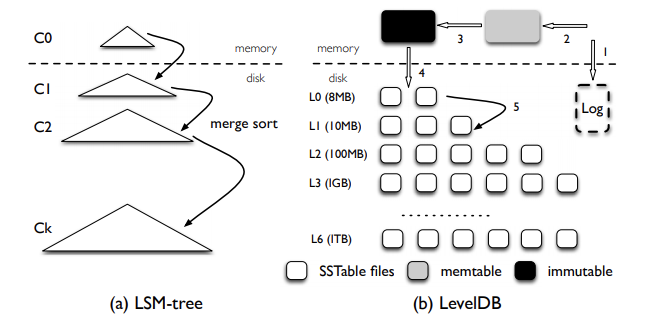
在内存中应该存在一个活跃内存表和一个不变内存表,二者相互交替,周期性的将不变内存表dump到内存中形成一个分段文件。
因为重叠key已经在其上一层被合并了。那么只有c0层是可能存在重叠的文件的。所以当要读取磁盘上的数据时,最坏情况下只需要读取c0的所有文件以及c1-ck每一层中的一个文件即c0+k个文件即可找到key的位置,分层合并思想使得非就地更新索引在常数次的IO中读取数据。
KV分离
wisckey中将key与value分离存储,value仅以追加的方式存储在vlog中,而key存储在之前的lsm tree结构中。
在sstable文件中数据布局: <key, addr(vlogName,offset,size)>
在vlog文件中的数据布局: <keySize,valueSize,key,Value>
由此,
不需要频繁移动value的值,所以写放大减少。
lsm仅存储固定大小的key,使得其存储占用变小,在内存中可以同时存储更多的key进而提高了缓存key的数量,间接的降低了读放大问题。
vLog文件会不断增大,那么就需要合并。合并的策略如何?LSM结构中维护的value的位置信息也要更新。数据具体如何布局?vLog日志如何拆分?wisckey崩溃后如何恢复才能保证数据的一致性呢?
优化
C0还是B+树。点查询可以首先搜索B+树的非叶子页面以找到叶子页面,在该叶子页面中假定非叶子页面足够小以进行缓存,然后检查关联的布隆过滤器,再获取叶子页面以减少磁盘I/O之前。
Gossip一致性协议
Gossip 算法是一个带冗余的容错算法,更进一步,Gossip 是一个最终一致性算法。又被称为反熵(Anti-Entropy):在一个有界网络中,每个节点都随机地与其它节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。
实际上 Gossip 可以用于众多能接受“最终一致性”的领域:失败检测、路由同步、Pub/Sub、动态负载均衡。缺点也很明显,冗余通信会对网路带宽、CUP 资源造成很大的负载,而这些负载又受限于通信频率,该频率又影响着算法收敛的速度。
消息
Gossip 协议的主要职责就是信息交换。信息交换的载体就是节点彼此发送的Gossip 消息,分为:
Meet 消息:用于通知新节点加入。
Ping 消息:集群内交换最频繁的消息,封装了自身节点和部分其它节点的状态数据。每个节点每秒向多个节点发送 Ping 消息,用于检测节点是否在线和交换信息。
Pong 消息:当接收到 Ping、Meet 消息时,作为响应消息回复给发送方确认消息正常通信。也封装了自身状态数据,节点也可以向集群内广播自身的 Pong 消息来通知整个集群对自身状态进行更新。
Fail 消息:当节点判定集群内另一个节点下线时,会向集群内广播一个 Fail 消息,其他节点接收到 Fail 消息之后把对应节点更新为下线状态。
对于Redis Cluster而言,node首先需要知道集群中至少一个seed node,此node向seed发送ping请求,接收到seed节点pong返回自身节点已知的所有nodes列表,然后与node解析返回的nodes列表并与之建立连接,同时也会向每个nodes发送ping,并从pong结果中merge出全局的nodes列表,并与之逐步建立连接。另数据传输的方式也是类似。
Lamport 逻辑时钟细节
分布式系统中按是否存在节点交互可分为三类事件,一类发生于节点内部,二是发送事件,三是接收事件。时间不一致的问题在节点交互上出现。
逻辑时钟(logical clocks),使用了自增的计数器,而非石英晶振(oscillating quartz crystal)。逻辑时钟不会追踪自然时间或者耗时间隔,而仅用来确定的系统中事件发生的先后顺序。 其将严格的物理时间戳比较拓展成偏序比较逻辑时间戳,表示为因果关系。即,如果事件$A\rightarrow B$(A
happens beforeB),则时间戳$T(A) < T(B)$. 逆命题不成立。
Lamport 逻辑时钟的定义规则:
每个事件对应一个Lamport时间戳,初始值为0
如果事件在节点内发生,本地进程中的时间戳加1
如果事件属于发送事件,本地进程中的时间戳加1并在消息中带上该时间戳
如果事件属于接收事件,本地进程中的时间戳 = Max(本地时间戳,消息中的时间戳) + 1
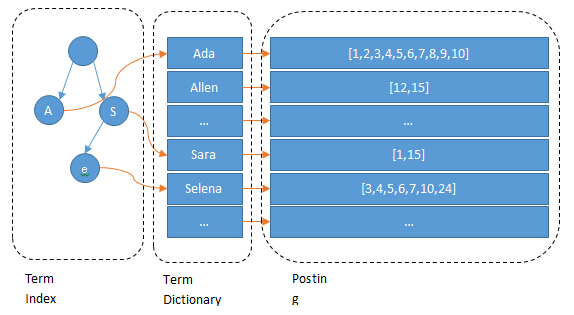
倒排索引
以查询某个单词在哪些文件中出现为例。
一个未经处理的数据库中,一般是以文档ID作为索引,以文档内容作为记录。而Inverted index 指的是将单词或记录作为索引,将文档ID作为记录,这样便可以方便地通过单词或记录查找到其所在的文档。
对记录进行分词,得到记录 -> 出现的文档ID集和频率信息(倒排项)
维护前缀树等,节省空间地指向倒排项。
最后更新于