静态软件分析-执行流
Intro

Intermediate Representation
3-address form

compact and uniform

eg: Java soot Method Call demo:

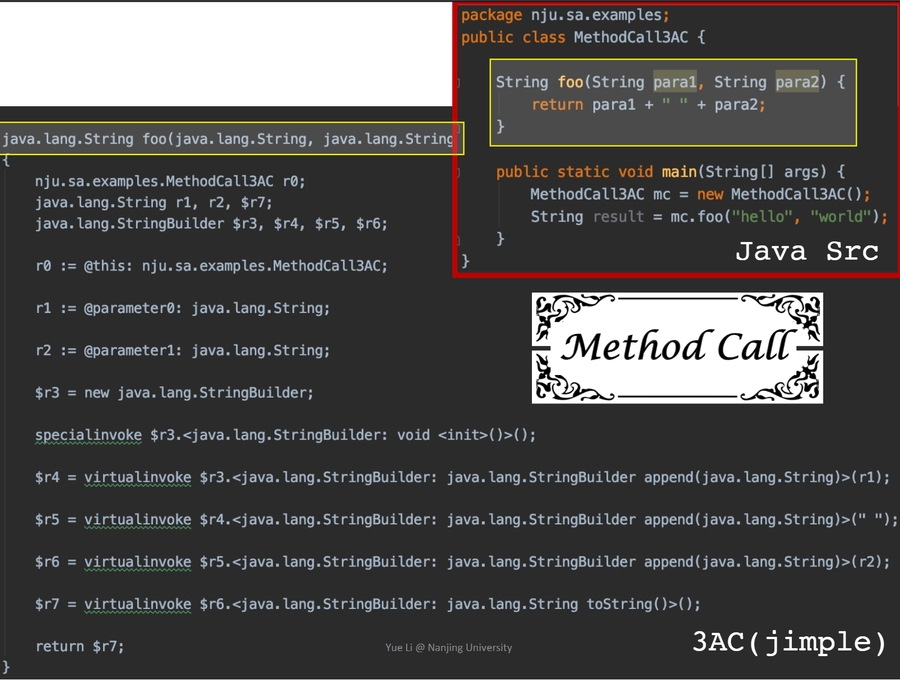
Static Simple Assignment(SSA)
Control Flow Analysis
Data Flow Analysis - AP
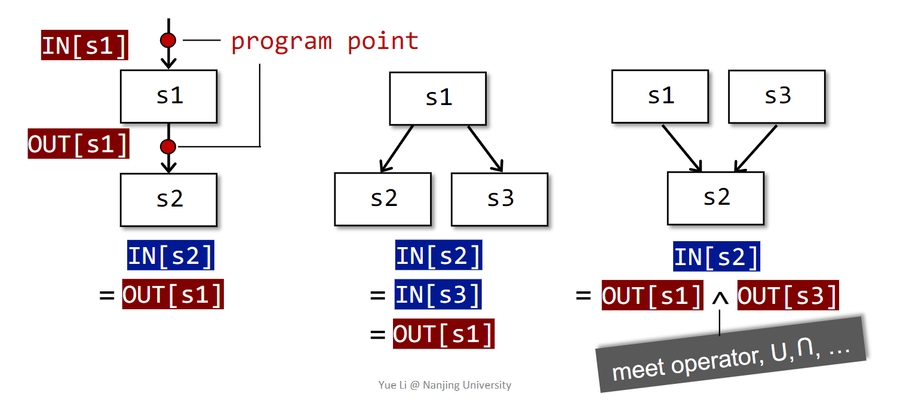
Preliminaries
状态机转换:
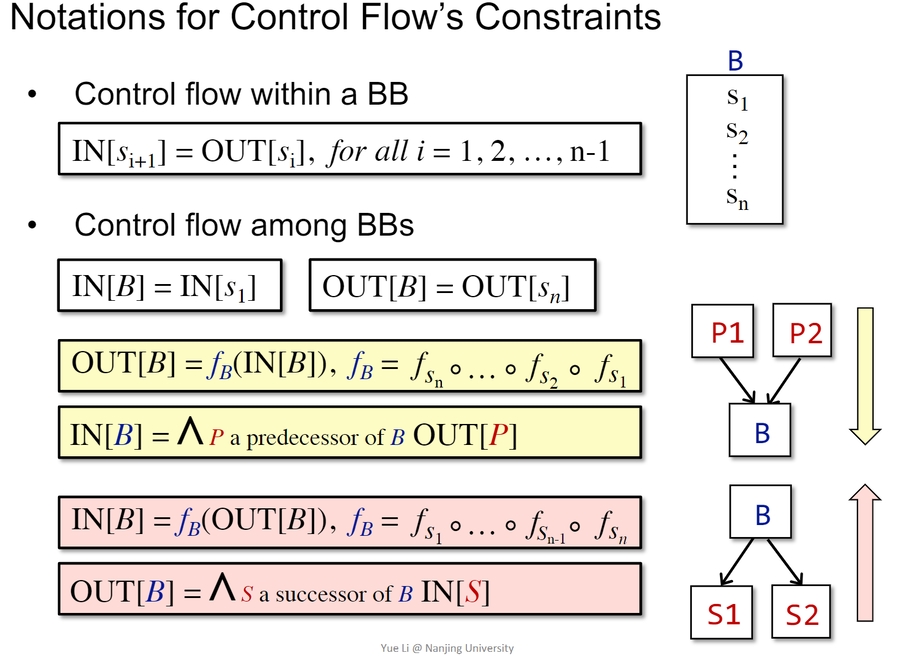
形式化描述:
Reaching Definition Analysis
 此算法的灵魂在于:
此算法的灵魂在于:IN[B]不变,则OUT[B]不变。(其他是常量) 此算法的有穷性表现为:IN的变化表示为“更多的流入信息”,信息流在静态程序中是有限的,因此OUT为单增的(只会set 1)。 从循环不变式的角度来说,由于IN完全依赖于OUT,因此终止条件是安全的不动点。
Live Variable Analysis
-> 此次定义未被use,则不必存入寄存器(v is dead at p) 
Available Expressions Analysis
after the last evaluation of x op y, there is no redefinition(
kill) of x or y 这是一个must analysis(under-approximation, safe)。 | 优化前 | 优化后(使用last evaluation) | | ---------------------------------------------------------- | ------ | | |
|  |
|

Analysis Comparison

Data Flow Analysis - FD

不动点定理
不动点:$f(V)=V$ 
Relate Iterative Algorithm to Fixed Point Theorem
May/Must Analysis, A Lattice View

Meet-Over-all-Paths(MOP)

每条path对应$F_p$操作的结果进行Meet或者Join。
有些path在软件跑起来时不会走这条路(executable)
很难在大程序中进行枚举(Unbounded)
($MOP\sqsubseteq OURS$OURS->Iterative Algo.) 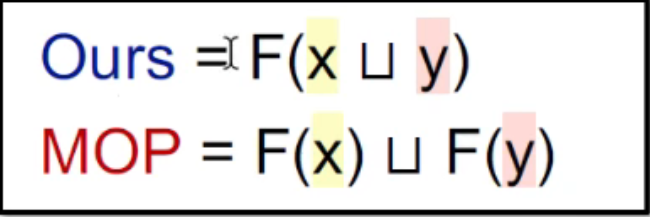
Constant Propogation


WorkList Algorithm

A1: 活跃变量分析和迭代求解器
LValue & RValue

【在LiveVariableAnalysis中你获得的道具】
A2:常量传播和 Worklist 求解器
 很容易发现,
很容易发现,Exp类是非常核心的一个类。(翻译:表达式包含变量、字面量、二元表达式三种,你需要在某个地方判断是哪种或者需要分类讨论)我们不妨先复习几个概念:
实现细节
道具:表达式求值
A3:死代码检测
实现设计
实际上,fallthrough已经在CFG实现,而不是通过
canFallthrough方法判断的,我这里的处理方式是将其他的分支直接出队,而不是重复遍历。 因为生成的IR图是这样的,所以你不必按类似于查找表的方式处理它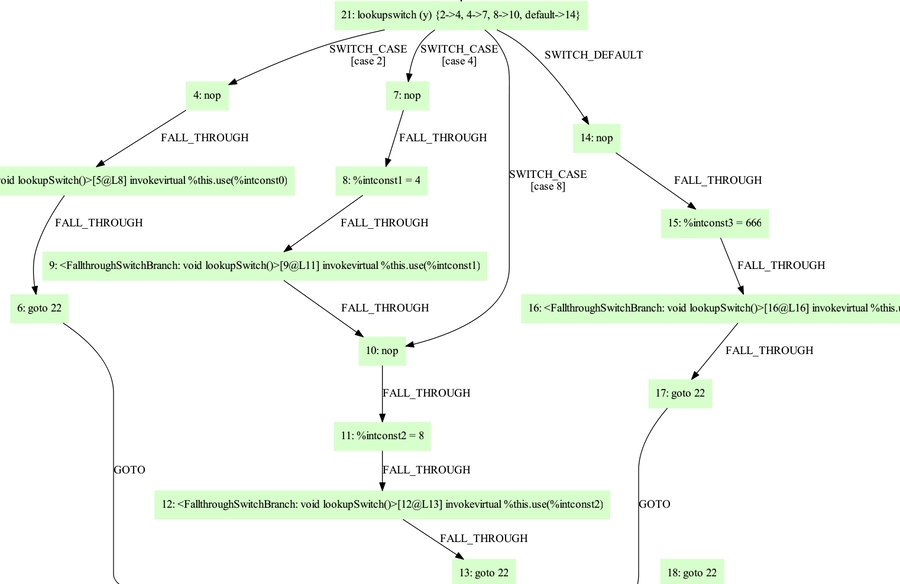
道具:右值副作用
最后更新于